A TextLibben a keresőnyelven egy több utasításból álló programot (az ún. keresőkérdést) lehet megfogalmazni. A nyelvben a keresésen kívül vannak utasítások az indexes és mező alapján való projekció, halmazműveletek és halmaz szűkítés végrehajtására is. A keresőkérdések használata a rendszergazdai dokumentációban van részletesebben leírva, itt most a nyelv bemutatásával foglalkozunk.
A keresőnyelv egy vagy több utasításból áll. Az utasítások leírása itt következik, csak olyan szinten, hogy meg lehessen érteni.
Újak:
Az utasítások leírásában a kulcsszavakat nagybetűvel jelöltük, a zárójelek közötti részek elhagyhatók, a ... pedig az ismételhetőséget jelenti. Minden kulcsszó használható rendes ékezetes (pl:SZŰKÍTS), rövid ékezetes (Pl:SZÜKITS) és ékezet nélküli (pl:SZUKITS) formában is. Ennek gyakorlati okokból lesz jelentősége, pl. a valamikori távoli elérésnél (Internet,BBS) nem biztos, hogy mindenki tud használni ékezetes betűket.
A legtöbb utasítás leírásában szerepel az
[sx =]
Az utasításokban hivatkozhatunk a keresőkérdésben már definiált sx halmazokra, és a TextLibben korábban létrehozott találati halmazokra is. Az előbbiekre a nevükkel (pl: s1, s2) az utóbbiakra pedig az & jel után írt nevükkel (pl: &Modosult, &H3), vagy szerver-beli akár sorszámukkal (&1153).
Egy tárolásra szánt keresőkérdésben általában nem érdemes létező halmazokra hivatkozni, hiszen nem biztos, hogy ilyen nevű halmaz létezni fog a kérdés futtatásakor. (Azért persze vannak kivételek, pl. a Bevitt és a Módosult halmazok esetleg jól használhatók).
Az utasításokban azokat a helyeket, ahol mind a kétféle halmazra lehet hivatkozni, hx-szel jelöltük.
Az utasításokat pontosvesszővel, vagy soremeléssel kell elválasztani egymástól.
Az utasítások elé, közé megjegyzéseket rakhatunk a kapcsos zárójelek segítségével. Érdemes az első sorba egy sokat mondó megjegyzést írni, mert a keresés eredményeképpen előálló halmaz megjegyzésében ez fog látszani.
Ha ebbe a megjegyzésbe beírjuk a felhasznált paraméterek neveit, akkor a létrejövő halmaz megjegyzésében ezek helyett a megadott paraméter értékek fognak szerepelni. Lássunk erre egy példát:
A keresőkérdés:
{Az %1 szot tartalmazo konyvek}
KERESS szavak=%1
NEVEZD %1 "Cim szava:",szavak
A futtatáskor megadott paraméter érték: alma
A létrejövő halmaz megjegyzése: Az alma szot tartalmazo konyvek
[sx =] KERESS [adatfile[ ÉS adatfile...]] [REKORDOKAT][,][AHOL] kifejezés
A legfontosabb utasítás, ezzel lehet az indexfile-okban keresni. A kifejezés több kisebb keresőkifejezés operátorokkal (ÉS,VAGY,DE NEM) való összekapcsolásából állhat. A keresőkifejezés pedig három részből áll: egy indexfile-névből, egyenlőség jelből, és egy keresendő kifejezésből. Ha a szövegben kulcsszó, vagy speciális karakter (pl: =, ?, &, --) szerepel, akkor " vagy ' közé kell tenni. A két jel közül az nem fordulhat elő a szövegben, amelyikkel a szöveget kezdtük.
Pl: Szöveg
"Nem egy -- intervallum, csak szöveg"
"Szöveg ' jellel"
'"Idézet" van benne'
"Van benne egy és kulcsszó"
"Szóköz is" -- "van az intervallumban"
"@ karakterrel kezdődő szöveg"
A szöveg lehet:
- konkrét érték (idézőjellel, vagy anélkül)
- csonkolt érték (az első és/vagy utolsó karaktere egy kérdőjel Pl: Arany?)
- teljes intervallum (a -- az intervallum jele. Pl: Arany--Petőfi)
- nyílt intervallum (Pl: Arany--, --Petőfi )
- Dátum helyettesítő: MA(), HOLNAP(), TEGNAP(), MA(+4), MA(-3), MA(%1)
Speciális eset (1609 verzió): a kifejezés lehet egy rekord azonosító is.
Ekkor egy '@' jel után jön a rekord dref. Pl: @f70
Csak kapcsolódó és dref-es indexeknél használható:
KERESS szerzo=@f70
KERESS ejreszleg=@az12792.2
Néhány példa talán érthetőbbé teszi a dolgot:
KERESS Szerző=Arany? KERESS REKORDOKRA, AHOL Szerző=Arany? VAGY Közreműködő=Arany? KERESS audiókötet ÉS audiódok AHOL Szerző=Arany? DE NEM Szerző="Arany Dezső" KERESS Szerző=Arany--Petőfi? VAGY Cím="Merre menjek?" KERESS alkotó REKORDOKRA AHOL Alkotónév=Arany? KERESS kolcs REKORDOKRA AHOL kiadva=MA() KERESS kolcs REKORDOKRA AHOL kiadva=MA(-3)--TEGNAP() KERESS Szerző=@f70
Az indexfile-ok neveit (és azt, hogy az indexfile-ba milyen rekordok indexelődnek a DBSTRUCT programmal tudhatjuk meg. A TextLibben az indexfile-ok neveit technikai okokból ékezet nélkül használjuk, de a keresőnyelvben az ékezetes változat is használható. A SZERZO indexfile-ra tehát hivatkozhatunk 'Szerző' és 'Szerzö"-ként is.
Az adatfile-ok megadásához az adatfile-ok nevét is használhatjuk. Lehetőség van azonban arra is, hogy az 'Általános keresés' ablakból megismert nevekkel hivatkozzunk egyszerre több adatfile-ra. A 'könyv' például a kötet és a dok adatfile-okat jelenti. Az ily módon használható nevek tehát:
[sx =] hx [sx =] (dref=dref2,dref2,dref3,...) [sx =] halmazkif ÉS halmazkif [sx =] halmazkif VAGY halmazkif [sx =] halmazkif DE NEM halmazkif [sx =] ( halmazkif )
s4 = s1 ÉS s2 DE NEM s3 s5 = (s1 VAGY s2) ÉS s3 s2 = &Modosult VAGY &Bevitt VAGY s1 s5 = (dref=b1,b2,b3,b4,b5)
VETITS - indexes projekció
[sx =] VETITS [adatfile[ ÉS adatfile...]] [REKORDOKRA] hx [REKORDOKBÓL]
indexfile[ ÉS indexfile...] [INDEX] [SZERINT]
Ezzel az utasítással tudjuk például egy szerzőket tartalmazó indexfile-ból megkapni az ő könyveiket.
s1 = KERESS Alkotónév=Arany? VAGY Testületnév=Arany? VETITS s1 Szerző ÉS Közreműködő ÉS Kiadó SZERINT VETITS kötet REKORDOKRA &Modosult REKORDJAIT Szerző SZERINT
UTALJ - mezős projekció
[sx =] UTALJ [adatfile[ ÉS adatfile...]] [REKORDOKRA] hx rekordtípus
[REKORDOKBÓL] mező[ ÉS mező...] [MEZÖ] [SZERINT]
A mezőt meg lehet adni a nevével és a sorszámával. Utóbbi esetben a # karakter jelzi, hogy mező sorszám következik. Ez a megoldás gyorsabb fordítást eredményez, és kevesebb memóriát igényel, mivel nem kell betölteni a mezőneveket (ami 30-40 Kbyte összesen).
Almezők kezelésének kétféle módja van. Ha csak az almező nevét adjuk meg, akkor a benne található összes pointeres mezőre történik a projekció. Ha pontosítani akarjuk a dolgot, akkor mező.mező alakban adhatjuk meg, hogy az almező mely mezőjére gondolunk. Mindkét felében használható a mezőnév és a sorszám is.
Az utasításnak meg kell adni a rekordtípust is, mert enélkül a mező megadása teljesen értelmetlen lenne. Ha olyan rekord is van a halmazban, ami nem ilyen típusú, akkor az figyelmen kívül marad.
Ezzel az utasítással lehet például egy könyveket tartalmazó halmaz szerzőit összegyűjteni egy másik halmazba.
s1 = KERESS Cím=Egri? UTALJ Alkotó REKORDOKRA s1 dokumentum REKORDOKBÓL Szerző MEZÖ SZERINT s1 = KERESS Cím=Egri? UTALJ s1 dokumentum #70 s1 = KERESS Cím=Egri? UTALJ s1 dokumentum közreműködő.valaki
VALOGASS - válogatás halmazból
[sx =] VALOGASS hx rekordtipus [REKORDOKBOL] mezőkifejezés [sx =] VALOGASS hx xadatfile ADATFAJL [REKORDOKBOL] mezőkifejezés
A mezőt meg lehet adni a nevével és a sorszámával. Utóbbi esetben a # karakter jelzi, hogy mező sorszám következik. Azért kell megadni a rekordtípust, mert enélkül a mező neve nem értelmezhető.
Ha olyan rekord is van a halmazban, ami nem a megadott rekordtípusú ill. nem a megadott adatfájlba tartozik, akkor az figyelmen kívül marad.
Figyelem: xadatfile csak valódi adatfájl név lehet (pl. dok, kötet), a máshol használható elvi adatfájlok (pl. könyv,cikk,időszaki) itt nem működnek.
A mezőkifejezés lehet
mezo URES mezo NEMURES mezo BENNE [van] halmaz [HALMAZBAN] mezo NINCS BENNE halmaz [HALMAZBAN] mezo=ertek ( != < <= > >= ) mezo~=ertek ( ~!= ) mezo#=ertek ( #!= #< #<= #> #>= ) ( mezőkifejezés VAGY mezőkifejezés) ( mezőkifejezés ÉS mezőkifejezés) ( mezőkifejezés DE NEM mezőkifejezés)
Nem minden mezőtípusra van minden relácio megengedve. Pl. dref mezőnél nincs értelme a < és > vizsgálatnak.
Ezzel az utasítással lehet például egy könyveket tartalmazó halmaz olyan rekordjait kigyűjteni, akiknek egy konkrét mezőjéről tudunk valamit.
s1 = KERESS Cím=Egri?
{ Alcim nelkuli dokumentumok }
VALOGASS s1 dokumentum REKORDOKBÓL ALCIM URES
{ A bevittek kozul valogassunk }
VALOGASS &BEVITT dokumentum REKORDOKBÓL ALCIM URES
{ Speci esetben, ha a halmaz sorszamat tudjuk }
VALOGASS &1154 dokumentum REKORDOKBÓL ALCIM URES
{ 'Egri' kezdetu alcimuek }
VALOGASS s1 dokumentum ALCIM="Egri?"
{ 'Egri' kezdetu alcimuek }
VALOGASS s1 dokumentum ALCIM="Egri?"
{ adott napon bevittek kigyujtese }
VALOGASS s1 dokumentum BEVITEL=20100412
{ Biblia cimuek, amiknek van egysegesitett cimuk }
VALOGASS (KERESS cim=biblia) dokumentum egyscim NEMURES
{ alkotok keresese, akiknek van foglakozasuk }
VALOGASS (KERESS ALKOTONEV="?") alkoto foglalkozas NEMURES
{ s1 (kolcsonzesek) kozul azok, amiknek a kolcsonzoje benne }
{ van az s2 (olvasok) halmazban }
VALOGASS s1 kolcs rekordokbol kolcsonzo benne van s2 halmazban
{ s1-bol a mai kolcsonzesek valogatasa }
VALOGASS s1 kolcs kivive==MA()
{ s1-bol a 2016-os kolcsonzesek valogatasa - regexp-el }
VALOGASS s1 kolcs kivive~='2016.*'
{ s1-bol a 2016-os kolcsonzesek valogatasa - intervallum }
VALOGASS s1 kolcs kivive='20160101--20161231'
{ s1-bol kolcsonzesek valogatasa - intervallum }
{ Futtataskor megadhato parameter: 20160101--20161231 }
VALOGASS s1 kolcs kivive=%1
Vagy ha több mezőt kell nézni egyszerre:
VALOGASS s1 dokumentum (ALCIM NEMURES vagy ALCIM="regény") VALOGASS s1 dokumentum (BEVITEL>20100101 es BEVITEL<20101231)
A mezők ismétlődés számának vizsgálatára szolgálnal a '#' relációk. Ha pl. azokat az olvasókat kell lekeresni, akiknek egynél több email címük van:
valogass (keress olvnev=?) user email #> 1
Meg lehet adni almezőt és hivatkozó mezőt is. Utóbbinál meg kell adni a hivatkozott rekord tipusát is, mert a nélkül nincs értelme mezőnévnek.
{ dokumentumokbol: amiknek van sorozatleirasuk, es abban van sorozatiszam }
VALOGASS s1 dokumentum sorozatleiras.sorozatiszam NEMURES
{ 563-as kezdetu vonalkodu peldanyokbol azok, amiknek a kotetenek }
{ a szerzoje az 1400-as evekben szuletett... }
valogass (keress vonalkod=563?) peldany kotete.(dokumentum)szerzo.(alkoto)evek = "14?"
{ kolcsonzesekbol azok, amelyek kolcsonzojenek van email cime }
valogass (keress kiadva=20120102) kolcs kolcsonzo.(user)email nemures
Szükség lehet arra is, hogy ha a mező megfelelés egy almezőben van, akkor csak az almező egy adott ismétlődése képezzen találatokat. Az adott ismétlődésig egyezést a csoportosító operátorral lehet leírni, azt pedig, hogy az adott mező része a csoportnak, .mező formában. A csoportosítás addig van érvényben amíg .mező módon van megadva a logikai operátor után a következő feltétel mezője.
{ Akik 2011-ben iratkoztak be valamelyik kistersegi intezmenybe }
valogass (keress userazon=?) user [intkent].beiratkozasa >= 20110101 es .beiratkozasa <= 20111231
{ 2011-ben a térségi ellátó könyvtárba (ah1) beiratkozottak listája }
valogass (keress userazon=?) user [intkent].beiratkozasa >= 20110101 es .beiratkozasa <= 20111231 es .intezmeny = ah1
Reguláris kifejezést is használhatunk, erre szolgál a ~= Ha pl. azokat az olvasókat kell lekeresni, akiknek három nevük van, akkor:
valogass (keress olvnev=?) user nev ~= '([a-z]+ ){2}([a-z]+)'
SZÜKITS - halmaz szűkítése
[sx =] SZÜKITS [adatfile[ ÉS adatfile...]] [REKORDOKRA] hx [REKORDOKBÓL]
Találati halmazt tudunk ennek az utasításnak a segítségével leszűkíteni oly módon, hogy csak a felsorolt adatfile-beli rekordok maradjanak benne. Ez gyakorlatilag megfelel a Halmaz adatai ablakban is végrehajtható halmaz szűkítésnek.
SZÜKITS dok ÉS kötet s1 SZÜKITS testület ÉS rendezvény REKORDOKRA s1 REKORDOKBÓL SZUKITS alkoto REKORDOKRA &Modosult REKORDOKBOL
RENDEZD - halmaz rendezése
RENDEZD hx [HALMAZT] rendezes [SZERINT]
rendezes - a rendezési formátum neve (ez esetben " jelek közt), vagy dataref-je (ez esetben " nélkül). A rendezési formátum nevét lehet csonkolni, de ha így nem lesz egyértelmű, melyik rendezés kell, akkor a rendezés sikertelen lesz!
Rendezési formátum helyett lehet ún. formalista nevet adni, ez főleg profiknak kell, akik tudják mi is ez... #formalista alakban kell megadni.
A keresőkérdés bármely halmazát lehet ezzel helyben rendezni. Viszont a halmazműveletek jelenleg csak nem rendezett halmazon használhatóak, így praktikusan az eredményhalmaz rendezésére használható. Meg lehet adni a rendezési formátum nevét vagy dataref-jét.
RENDEZD (KERESS CIM=) ar22.2 RENDEZD s2 HALMAZT "Dokumentumok cim es szerzo?" SZERINT rendezd &H2 halmazt ar22.2 szerint rendezd (valogass (keress cim=biblia) dokumentum alcim NEMURES) "dok cim?" rendezd (keress userazon=?) #default
Nem lenne sok értelme keresőkérdéseket tárolni, ha nem lehetne ezeknek paramétereket megadni. Ennek használata igen egyszerű. A KERESS utasításban a keresett érték helyén, és a halmazokra vonatkozó utasításokban (UTALJ, VETITS, SZÜKITS) konkrét érték helyett a %1, %2, %3, ... %9-et használjuk (a DOS batch file-okhoz hasonlóan). Pl.
KERESS Szerző=%1 VAGY Közreműködő=%1 KERESS Szavak=%1--%2
Pl: KERESS cim=%1?
Pl: KERESS cim=?%1?
KERESS cim=?%1
Pl: KERESS szerzo=@%1
Pl: SZUKITS Alkoto REKORDOKRA &%1 REKORDOKBOL
NEVEZD %i paraméter neve[, indexfile]
Minden paraméterhez tartozhat egy NEVEZD utasítás. Ha az indexfile-t is megadjuk, akkor lehet expandot kérni a paraméter megadásakor. Amennyiben %i halmaz paraméter, akkor annak megadásakor halmazt kell választani.
A NEVEZD utasításokat célszerű a keresőkérdés végére írni, mert a képződő alálati halmaz megjegyzése a keresőkérdés eleje lesz.
Pl: NEVEZD %1 "Alkotó neve:",Alkotónév
NEVEZD %2 "Könyv címe:",Cím
NEVEZD %3 "Mi legyen a halmaz:"
Keressük az adott című audiovizuális dokumentumokat
KERESS audiódok és audiókötet rekordokat, ahol cím=%1? NEVEZD %1 "Audióviz. cime:",cim
Keressük le egy folyóirat valamennyi számában megjelent összes cikket
{Folyoirat cikkei}
KERESS időszaki cím=%1
VETITS időszám REKODOKRA s0 REKODOKBOL időkötete INDEX SZERINT
UTALJ cikk REKORDOKRA s0 időszám REKODOKBOL analitika MEZO SZERINT
NEVEZD %1 Folyóirat:,cim
Keressük le a paraméterként megadott nevű alkotók könyveit. A szerző nevét csonkoltan megadottnak tételezzük fel.
KERESS alkotónév=%1? VETITS kötet és dok rekordokra S0 rekordokból szerző index szerint NEVEZD %1 "Alkotó neve:",Alkotónév
Az előző példa ellentéte: a paraméterként megadott című könyvek szerzőit gyűjtsük össze.
KERESS cim=%1? UTALJ rekordokra S0 dokumentum rekordokból Szerző mező szerint; NEVEZD %1 "Könyv címe:",cim
A következő példa szinte mindent felvonultat, amire a nyelv képes. A feladat az, hogy egy alkotó, mint szerző vagy közreműködő audiovizuális műveit találjuk meg. A szerzőnek több névváltozata is van, és mindegyik alapján minden művét meg kell találni.
{Alkotó (%1) audiovizuális műveinek keresése}
{Először meg kell keresni magát az alkotót}
s1 = KERESS alkotó REKORDOKRA, AHOL Alkotónév=%1?
{ Aztán előszedjük az egységesített nevét, (ha van) }
s2 = UTALJ alkotó REKORDOKRA s1 alkotó REKORDOKBÓL egysnev MEZÖ SZERINT
{ Ezt a kettőt rakjuk egybe, nem tudni melyik volt az egységes név}
s3 = s1 VAGY s2
{ Most vegyük elő a névváltozatokat. (Az s1,s2 már nem kell.) }
s4 = UTALJ alkotó REKORDOKRA s3 alkotó REKORDOKBÓL Névváltozat MEZÖ SZERINT
{ Ezt adjuk hozzá a egységesített névhez }
s5 = s3 VAGY s4
{ Ezeknek szedjük elő az audiovizuális műveit }
VETITS audiókötet és audiódok REKORDOKRA s5 szerző és közreműködő SZERINT
{ Ezzel előállt a kívánt halmaz}
{ Megadjuk, hogy a paraméter bekérésnél mit kell majd kiírni}
NEVEZD %1 "Alkotó neve:",Alkotónév
A keresőkérdés megfogalmazásakor elég sok hibalehetőség adódik. Itt most felsoroljuk ezeket, és tippeket adunk a kijavításukra is.
Azt jelenti, hogy a keresőkérdés formailag nem felel meg a kívánalmaknak. Egy módon lehet megszüntetni, ki kell javítani.
Egy olyan helyen, ahol adatfile nevét várja a program, nem megfelelő szöveget talált.
A KERESS kulcsszó után csak ezek jöhetnek:
Nem létező index nevet adott meg.
Nem létező rekordtípus nevet adott meg.
Az aktuális rekordtípusban nem létező mezőnevet adott meg.
A mezőneveket tartalmazó modul betöltése nem sikerült. Ezért aztán nem használhat mezőneveket a keresőkérdésben. Vagy megoldja, hogy sikerüljön betölteni a mezőneveket, vagy a mezőkre sorszámmal kell hivatkoznia.
Az aktuális rekordtipusban érvénytelen mező sorszámot adott.
Egy Sx halmaznak nem adott értéket, de fel akarja használni.
Egy Sx halmaznak adott értéket, de nem használta fel. Ez csak az S0 halmaz esetében nem gond, hiszen az lesz a keresés eredmény halmaza.
Egy Sx halmaznak értéket adott, és mielőtt felhasználta volna, újra értéket akar adni neki. Igy az előző értéke elveszik.
Pl: s3 = keress cimszo=alma? s3 = keress cimszo=korte
Egy olyan helyen, ahol adatfile-ok, indexfile-ok, mezők, stb listáját adhatja meg, túl sokat adott meg, vagy a keresés túl sok utasításból áll.
A paramétereket nem folytonosan számozta be. Használja például a %3-at, de a %2 nem szerepel a kérdésben.
Pl: keress cimszo=%2
Ezt a hibaüzenetet a kérdés futtatásakor kaphatjuk, ha olyan halmaz nevét adtuk meg a kérdésben, vagy a paraméter értékeként, ami nem létezik.
Az UTALJ utasításban csak olyan mezőt adhat meg, ami kapcsolódó mező, vagy almező.
Ha olyan keresőkérdést visz be, amit projekcióként akar használni, akkor a keresőkérdésnek egyetlen - halmaz - paramétere lehet csak!
A TextLibben az output nyelv segítségével lehet leírni, hogy az egyes rekordokat milyen módon kell megjeleníteni (nyomtatón, file-ba, képernyőre). A rekord megjelenítésénél felhasználhatók konstans szövegek, a rekord mezői és almezői, a kapcsolódó mezők által hivatkozott (és az azok által hivatkozott...) rekordok mezői is. Egy könyv rekord megjelenítésénél tehát gond nélkül megjeleníthető a könyv szerzője, annak egységesített nevével, foglalkozásával, stb. együtt.
Mivel a TextLib adatszerkezete meglehetősen bonyolult, ennek megjelenítésére egyszerű output nyelv nem lett volna alkalmas. Használatát csak programozási gyakorlattal (BASIC, C, Pascal stb.) rendelkezőknek javasoljuk.
A nyomtatási formátum definiálásánál jelenleg úgy kell eljárni, hogy a lap méretein (sorok száma, oszlopok száma, stb) kívül meg kell adni egy nyomtató modul (Pl: TH_CEDUL) nevét (és annak paramétereit) is.
Az output nyelven megírt programot egy külön fordítóprogrammal lehet lefordítani, ami egy olyan TextLib modult készít, amit a nyomtatási formátum definiálásánál felhasználhatunk. (Lásd:itt)
Egy találati halmaz nyomtatása rekordoknként történik. A találati halmaz minden egyes rekordjára meghívódik az output nyelvben definiált PROG() nevű eljárás (ilyen nevű eljárást kötelező definiálni). Ez az eljárás kell, hogy elintézze ennek a rekordnak a megjelenítését. Le tudja kérdezni az aktuális rekord rekordtípusát, és ettől függően különbözőképpen tud nyomtatni.
A rekord kapcsolódó mezőibe is átmehetünk a megfelelő eljárások segítségével (CALL, RCALL), azokból visszatérve az aktuális rekord ugyanaz, mint azok meghívása előtt volt. Ha egy könyv rekord az aktuális, akkor pl. a szerző foglalkozását nem lehet azonnal megjeleníteni, csak úgy, ha átmegyünk a szerző rekordba, ahol már használhatjuk a 'FOGLALKOZAS' nevű mezőt.
Az output nyelven megírandó program tartalmazhat tetszőleges számú, a felhasználó által definiált eljárást (lásd: PROC), amik a program más részeiből hívhatók. Az eljárásoknak paramétereik is lehetnek, visszatérési értékük INT típusú.
Definiálhat a felhasználó olyan eljárásokat is (lásd: REC_PROC), amik egy adott rekord- vagy filetípusba tartozó rekord kezelésére alkalmasak. (Az, hogy egy rekord milyen adatfileba tartozik automatikusan eldönti a típusát.) Csak ilyen eljárásokban lehet rekordok mezőire hivatkozni, mivel a mező neve a rekordtípus megadása nélkül értelmetlen.
Lehetőség van egy BEFORE_PROG() és egy AFTER_PROG() eljárás definiálására is. Az első a nyomtatás előtt hívódik meg, ilyenkor például fejlécet lehet nyomtatni a rekordok elé. A második pedig az utolsó rekord nyomtatása után kerül meghívásra, itt lehet pl. valamiféle összegzést kinyomtatni.
Mint a legtöbb programnyelvben, az output nyelvben is többféle típusú értékkel, változóval dolgozhatunk:
| CHAR | '' jelek közti tetszőleges betű, ill. -128 - 127 közti egész szám |
|---|---|
| INT | egész szám -32768 - 32767 között |
| LONG | egész szám -2.147.483.648 - 2.147.483.647 között |
| DATE | dátum |
| STRING | szöveg |
| DREF | TextLib rekord aznosító |
Vannak olyan típusok, amikkel saját magunk nem definiálhatunk változókat, de lehetnek beépített változók vagy beépített eljárások visszatérési értékének és paramétereinek típusai:
| FLD | mező sorszám; csak a kérdéses rekordnál érvényes sorszám, ill. mező konstans ('#mezőnév') lehet |
|---|---|
| FLDNO | egész szám 1 - 255 között |
| DFILE | TextLib adatfile azonosító |
| RECTYPE | TextLib rekord típus |
A felsorolt típusok mindegyike helyett definálhatunk INT típust.
megjegyzés
Megjegyzésnek számít a /* és */ jelek közé tett tetszőleges szöveg, akár új sorok is, és a // jelek utáni szöveg, egészen a sor végéig.
konstansok
A program tartalmazhat szám konstansokat, amiket a szokott módon kell megadni, pl: 154.
Egy mezősorszám konstans van, amit mindenhol használhatunk, ez a ##FOMEZO. Ez a rekordnak az első nem üres főmezőjét jelenti. Ha egy tetszőleges rekordnak a leginkább jellemző adatát akarjuk kiírni, nem kell minden rekordtípusra írni egy eljárást, egyszerűen kiírjuk a főmezőjét, és kész.
A konstans szövegeket idézőjelek vagy aposztrófok közé kell tenni. Ha a szöveg tartalmazna idézőjelet, akkor tegyük aposztrófok közé, ha aposztrófot tartalmazna, akkor idézőjelek közé. Ha mindkettőt, akkor szedjük két részre a szöveget.
Az alábbi lista felsoroja az összes speciális jelet és hatását a nyomtatásra:
| Jel | Jel hatása a nyomtatásra |
|---|---|
| \\ | backslash, '\' karakter nyomtatás |
| \n | soremelés (mindenképp) |
| \s | soremelés (ha nem a Sor elején állunk) |
Beépített konstansok
A programban az adatfile, rekordtípus, indexfile és mezőnevek, mint konstansok használhatók. Az adatfile neveket '_df', a rekordtípusokat '_rt', az indexfile neveket '_if' végződéssel kell ellátni, a mezőnevek pedig a '#' karakterrel kezdődnek. (Megjegyezzük, hogy mező megadásának csak olyan helyeken van értelme, ahol a rekordtípus már ismert, vagyis a REC_PROC típusú eljárásokban. Kivételt képeznek a rekordok rendszer mezői, mert ezeknek, a rekord típusától függetlenül ugyanaz a nevük).
Beépített változók (nem módosíthatók)
| Változó | Jelentése |
|---|---|
| DREF CURRDREF | az aktuális rekord TextLib azonosítója |
| DFILE CURRDF | az aktuális rekord TextLib adatfile azonosítója |
| RECTYPE CURRRT | az aktuális rekord TextLib azonosítója |
| LONG INUM | a halmaz éppen feldolgozás alatt álló elemének sorszáma |
| LONG ISIZE | a halmaz elemeinek száma |
| INT RNO | a feldolgozás alatt álló ismétlődő mező sorszáma |
| INT ROW | az éppen készülő sor sorszáma |
| INT ROWNUM | az egy lapra nyomtatható sorok száma (konstans) |
| INT COL | az éppen készülő sor oszlop-pozíciója |
| INT COLNUM | az egy lapra nyomtatható oszlopok száma (konstans) |
| INT PAGENO | az éppen készülő lap sorszáma |
| INT PRINTED | a legutoljára - PRINT(), RPRINT() fv-ekkel - nyomtatott mező ismétlődéseinek a száma |
| STRING MODPAR | a nyomtató modul által kapott paraméter. Ez az, amit a nyomtatási formátum definiálásakor a Paraméter mezőben megadtunk. |
Beépített változók (módosíthatók)
| INT MARGIN | Bal margó. Ennyi SPACE kerül a sorok elejére. Default értéke 0. |
|---|---|
| INT KILLDOT | Kell-e figyelni, hogy egy pont kiírásakor ne írjuk ki, ha az előző karakter is ez volt. Pl: a '. -' kiírásánál szükség van rá. Célszerű BEFORE_PROG()-ban beállítani 1-re. Default értéke 0. |
| INT CUTROW | Le kell-e vágni a sorok végét. Ha 0-ra van állítva, akkor a sorba már ki nem férő szavak átkerülnek a következő sorba. Ha értéke 1, akkor a sorból kilógó szövegrészek elvesznek, egészen egy új sor kezdéséig. Akkor van szükség az utóbbi beállításra, ha pl. listát akarunk nyomtatni, ezzel lehet garantálni, hogy minden rekordról egyetlen sor készüljön. |
Felhasználó által definiált változók
| INT | név ,név...; |
|---|---|
| LONG | név,név...; |
| CHAR | név,név...; |
| DATE | név,név...; |
| STRING | név,név...; |
| DREF | név,név...; |
A változók különböző típusú értékek tárolására szolgálnak. Egy programban gyakran van szükség arra, hogy egy értéket félretegyünk, hogy később felhasználhassuk ill. műveleteket, számításokat végezzünk vele. A felhasználó tesztszőleges számú és típusú változót definiálhat. A definícióban először meg kell adnia a típusát, majd a nevét, amivel jelöli. Ezzel a névvel lehet rá hivatkozni később. A név tetszőleges számú nem ékezetes betűből és '_' jelből állhat, de az első kivételével számok is lehetnek benne. Több azonos típusú változót úgy definiálhatunk, hogy a típus után vesszővel elválasztva felsoroljuk a neveiket. A változó definíciót egy ';' zárja le.
A globális változóknak (a függvényeken kívül definiált változóknak) egyből értéket is adhatunk.
Értéket természetesen változónak lehet adni. Az értékadás jobb oldalán egy kifejezést vagy egy eljárást adhatunk meg:
{változó} = {kifejezés};
{változó} = {eljárás}({paraméterek});
IF ( feltétel ) { utasítások }; [ ELSE { utasítások } ]
Ezzel az utasítással tehetünk feltételtől függő elágazásokat a programba. A feltétel olyan kifejezés, amiben használhatjuk a <, <=, >, >=, =, <> relációs jeleket az OR, AND, NOT logikai operátorokat (ekvivalens megfelelőjük a ||, &&, !) és a () zárójeleket. Az utasításokat - kivéve, ha csak egy utasításról van szó - \ és \ zárójelek közé kell zárni.
Pl: IF ( RNO == 1 ) /* ha a rekord számláló 1 - az első előfordulás */
CPRINT("Ez az első rekord.");
else
CPRINT("Ez nem az első rekod.");
FOR ( értékadások; feltétel; értékadások ) { utasítások };
Ciklus szervezéséhez használható utasítás. Az első értékadások szokás szerint kezdőérték beállítások, a második a ciklusváltozók állítása. A ciklus utasításait, ha nem csak egyetlen egyről van szó, \\ zárójelek közé kell zárni.
Pl: /* Az összes közreműködő kinyomtatása */
INT Cikl;
FOR ( Cikl=1; Cikl<=FNUM(#VALAKI) ; Cikl=Cikl+1 )
KozremukodoNyomtatas( Cikl );
Az output nyelv elég sok beépített függvényt tartalmaz, amiknek a segítségével ki lehet nyomtatni az adatokat, pozícionálni lehet a lapon belül, mezők értékeit lehet vizsgálni, a dátumot lehet kezelni, stb. Lásd: outproc.txt
Az output nyelv lehetőséget ad arra, hogy eljárásokat definiáljunk. Kétféle eljárás létezik, egy teljesen általános (mint pl. a C függvényei), és a rekord kezelő eljárás. PROC és REC_PROC kulcsszavakkal különböztetjük meg őket. Az utóbbi annyival több, mint egy rendes eljárás, hogy meg kell adni azt is, hogy milyen rekordtípus kezelésére alkalmas. Csak egy ilyen eljárás belsejében lehet mezőnevekre hivatkozni, hiszen csak itt van ennek értelme.
Az általános eljárás a következőképpen definiálható:
[PROC] név([argumentumok]) { utasítások }
A rekord kezelő eljárás sem sokkal bonyolultabb:
[REC_PROC] név([argumentumok]) RekordTípus { utasítások } vagy
[REC_PROC] név([argumentumok]) AdatfileTípus { utasítások }
Pl: REC_PROC Alkoto(int fogl_kell) ALKOTO_rt
{ PRINT("Alkotó:",#NEV,"");
IF( fogl_kell )
PRINT(",foglalkozás:",#FOGLALKOZAS,"");
}
Pl: PROG main
{
IF( RT(CURRDREF) == DOKUMENTUM_rt )
KonyvNyomtat(0);
ELSE
CPRINT("Más rekord típus\n");
}
Pl: BEFORE_PROG Elotte
{ CPRINT("\n******** És most jönnek a rekordok: ********\n");
}
Egy részletes magyarázatokkal ellátott példát nézzünk meg.
Az output nyelven megírt programból OUTCOMP.EXE fordító programmal tudunk TextLib modult készíteni. Ennek a felhasználásával, egy új nyomtatási formátumot készítve, tudunk az output programnak megfelelő formában nyomtatni.
Fordítás:
Az OUTCOMP.EXE program a \TEXTLIB\PRINTER\ könyvtárban található és ide ajánlott tenni a fordítandó output programmot is. Igy, ha a \TEXTLIB\PRINTER\ könyvtáraba belépünk, az 1. ábra szerinti egyszerű paranccsal készíthetjük el az új nyomtató modult (az ábrán 'output program' az éppen fordítandó output program file nevét helyettesíti.), de ennek feltétele, hogy az output programban ne legyen hiba. Az új modul a \TEXTLIB\TLM\ könyvtárba kerül.
OUTCOMP {output program}
1. ábra
OUTCOMP.EXE egyszerű használata
A 2. ábra teljes részletességgel összefoglalja OUTCOMP.EXE használati lehetőségeit.
OUTCOMP[.EXE] {program} [{modul}] [/LIST]
[/P{modul könyvtár}] [/L{LOG file}]
{program} - output program file név.
Kiterjesztés: '.TOP',ha nincs megadva.
{module} - generált modul név. Ha nincs megadva, akkor
ua. mint {program}-ban a file név. Könyvtár:
ha nincs a névben, akkor /P szerinti.
Kiterjesztés: mindig '.TLM'. (Nem kötelező
megadni !)
/LIST - az output program listázása a képernyőre
fordítás közben.
/P{modul könyvtár} - az adatbázis leírás könyvtára. Ha nincs
megadva, akkor \TEXTLIB\TLM\.
/L{LOG file} - A LOG file neve. Ha nincs megadva akkor
OUTCOMP.LOG. Kiterjesztés: '.LOG',ha
nincs megadva.
2. ábra
OUTCOMP.EXE paraméterezésének összefoglalása
Hibaüzenetek:
A fordítás során OUTCOMP.EXE sorra értelmezi az output programban leírtakat és az ezzel kapcsolatos üzeneteket, valamint a fordítás eredményét nem csak a képernyőre írja ki, hanem az OUTPUT.LOG file-ba is rögzíti. Az üzenetek szerkezetét a 3. ábra mutatja.
{üzenet típus} {file név} {sorszám} : {üzenet szöveg}
{üzenet típus} - a üzenet fontosságát jellemző szöveg. 4 féle lehet:
"Megj." - Megjegyzés. Tájékoztató üzenet valamilyen
formai szabálytalanságról, eltérésről a
programban.
"Figy." - Figyelmeztető üzenet, valamilyen
lehetséges hibaforrásról a programban.
"Hiba " - Hibaüzenet, valamilyen hibáról a
programban.
"Krit." - Kritikus, súlyos hiba a programban ill. a
fordítás, modul készítés közben.
{file név} - a fordítandó output program neve
{sorszám} - output program azon sora, ahol hiba van ill.
azon sor, ahol éppen a fordításban a fordító hibát
fedezett fel.
{üzenet szöveg}- az üzenet okát, a hibát leíró szöveg
3. ábra
A hibaüzenetek formátuma
A fordító, típus szerinti csoportosításban, a következő üzeneteket írhatja ki:
Megjegyzések
Figyelmeztetések
Hibák
Kritikus hibák
Az output vagy nyomtató nyelvet új nyomtatási formák létrehozására használhatjuk. Ennek a menete röviden a következő:
A példa egy olyan egyszerű programocska (a program file neve REKLISTA.TOP), amely listát készít az éppen nyomtatott halmaz rekordjairól. Az 1. ábra egy példa, hogy néz ki a nyomtatás ezzel a programmal.
Listás halmaz nyomtatás:
1. a7 : A magyar mezőgazdasági szakirodalom könyvészete
2. a9 : A magyar bibliográfiák bibliográfiája
3. a14 : A Veszprém megyei múzeumok közleményei
4. b15 : A szúnyog
5. b17 : A politikai gazdaságtan bírálata
6. b21 : A szórakoztató biblia
7. b23 : Aegidius útra kelése és más történetek
8. b24 : A szerszámgépek karbantartása és jítása
9. b32 : A kötéltáncos
10. b33 : Az Újpesti Munkásotthon története
11. b34 : A Széchenyi tér regénye
12. d21 : Az Ókortudományi Társaság kiadványai
A halmazban 12 db rekord volt.
1. ábra
Példa nyomtatás REKLISTA.TOP programmal
A nyomtatás egy 12 elemű halmazból készült. Az első sor a fejléc majd ezután jönnek rekordonként az adatok: a rekord sorszáma a halmazban, adatbázis azonosítója, majd a főmezejének tartalma. A főmező a rekordokban az a mező, amely önmagában leginkább jellemzi a rekordot. Ebben a példában a halmaz könyv és sorozat rekordokat tartalmaz. Ezekben a főmező a főcím.
A program érdemi része a 2. ábrán látható. Ez érzékelteti a program röviségét. (A sorok elején a szám és ':' nem része a programnak, csak hivatkozási okok miatt került oda).
7: INT SZAMLALO = 0;
10: BEFORE_PROG Fejlec()
11: {
13: CPRINT( "Listás halmaz nyomtatás:\n" );
17: }
19: PROG Rekord_nyomtatas()
20: {
21: SZAMLALO = SZAMLALO+1;
22: NPRINT( "",SZAMLALO,4,". " );
24: DREFPRINT( CURRDREF );
26: TABTO( 15 );
29: PRINT( ": ",##FOMEZO,"\n" );
34: }
36: AFTER_PROG Lablec()
37: {
41: NPRINT( "A halmazban ",SZAMLALO,0," db rekord volt.\n" );
42: }
2. ábra
REKLISTA.TOP program (program sorok)
A 3. ábrán ugyanez a program van, de ki van egészítve a működés megértését segítő, magyarázó megjegyzésekkel. Általában ajánlott programjainkat ilyenekkel ellátni. Megjegyzéseket kétféle módon tehetünk a programba: '/*' és '*/' jelek közé, akár több sorban (pl. 1-5. sorig) és '//' jel után a sor végéig (pl. 7,8,10 stb. sorok vége).
1: /*** REKLISTA.TOP ***************************************************
2: **** ****
3: **** Találati halmaz listás nyomtatása - egy rekord egy sor ****
4: **** ****
5: **********************************************************************/
6:
7: INT SZAMLALO = 0; // változó a rekordok számlálására
8: // kezdőértéke : 0; típus : egész
9:
10: BEFORE_PROG Fejlec() // A fejlécet nyomtató eljárás
11: {
12: // szöveg nyomtatása a lista tetejére
13: CPRINT( "Listás halmaz nyomtatás:\n" );
14: // '\n' karakterpár = soremelés: hogy az
15: // első rekord nyomtyatása is a sor
16: // elején kezdődjön
17: }
18:
19: PROG Rekord_nyomtatas() // A rekordokat nyomtató eljárás
20: {
21: SZAMLALO = SZAMLALO+1; // a rekord számláló növelése 1-gyel
22: NPRINT( "",SZAMLALO,4,". " ); // a sorszám kinyomtatása: 4 betű
23: // szélességben és utána '.' és ' '
24: DREFPRINT( CURRDREF ); // az éppen nyomtatott rekord
25: // azonosítójának a nyomtatása
26: TABTO( 15 ); // pozicionálás a 15. oszlopig,
27: // hogy a kiírások egymás alatt,
28: // rendezetten kezdődjenek
29: PRINT( ": ",##FOMEZO,"\n" ); // a rekord főmezejének, a rekordot
30: // leginkább jellemző mező
31: // tartalmának kinyomtatása
32: // '\n' = soremelés: hogy a következő
33: // kiírás új sorba kerüljön
34: }
35:
36: AFTER_PROG Lablec() // A lista zárósorát nyomtató eljárás
37: {
38: // a lista végén a halmazban lévő rekordok számának kiírása:
39: // darabszám előtti szöveg; a rekordok száma (0, azaz) a szám
40: // méretének megfelelő hosszban; számláló utáni szöveg
41: NPRINT( "A halmazban ",SZAMLALO,0," db rekord volt.\n" );
42: }
3. ábra
REKLISTA.TOP program
A program a példa listának (1. ábra) megfelelően 3 fő részből áll. Ezek mindegyike egy eljárás. Eljáráson, vagy más szóval függvényen, olyan formailag is elkülönített programrészt értünk, amely a programon belül egy-egy (nyomtatási) részfeladatot old meg. A Fejléc nevű eljárás (10-17. sor) nyomtatja az első, fejléc sort, a Lábléc nevű eljárás (36-42. sor) nyomtatja az utolsó sort. A Rekord_nyomtatás eljárás (19-34. sor) feladata a rekodokról kiírni az egysoros információt. Míg az előző két eljárás a nyomtatás során csak egyszer hajtódik végre, addig ez többször, a találati halmaz minden egyes rekordjánál külön-külön, a rekordok halmaz beli sorrendje szerint. Az eljárások kezdő sorában a BEFORE_PROG, AFTER_PROG, PROG kulcsszavak jelölik azt a tulajdonságot, hogy a program elején, végén, vagy rekordonként végrehajtandó eljárásról van-e szó. Az ezeket követő eljárás név tetszőleges lehet. A kulcsszavak közül egyedül a PROG kötelező. A nyomtató programban mindig kell legyen egy olyan eljárás, ami ezzel jelzett.
Nézzük meg egy kicsit részletesebben a Fejlec eljárást (4. ábra). Egy eljárás leírása mindig a nevének és egyéb tulajdonságainak megadásával kezdődik (10. sor, Fejléc és BEFORE_PROG ), majd egy kapcsos zárójel pár ( '' és '' ) között a végrehajtó rész következik. A Fejléc függvényben ez csak egy rendszer eljárás hívás. Rendszer eljárás alatt azokat az eljárásokat értjük, amelyeket a rendszer (a TextLib) készen nyújt számunkra a programunk megírásához. Több ilyen eljárás létezik, itt csak azokat érintjük, amiket REKLISTA.TOP használ. A 13. sorban a CPRINT nevű eljárás írja ki a fejléc szöveget. Ez a rendszer függvény szövegek, szöveg részletek nyomtatására szolgál. Általában egy eljárásnak lehetnek paraméteri, azaz olyan bemenő adatai, amelyek befolyásolják, sőt alapvetően meghatározzák a működését. A paraméterek száma (ami esetleg 0 is lehet) és fajtája eljárásonként kötött. A paramétereket a függvény nevét követő kerek zárójelben ( '(' és ')' között ), vesszővel ( ',' ) elválasztva kell megadni. A CPRINT függvénynek egy paramétere van: az a szöveg, amit ki kell nyomtatni. Az eljárás közvetett módon, a szöveg végén lévő '\n' karakterpár segítségével, sort is emel, hogy a következő nyomtatás új sorban kezdődjön. Általános tulajdosága ennek a jelnek, hogy minden olyan helyen, ahova ezt írjuk, nem '\n' nyomtatódik ki, hanem egy új sor kezdődik a nyomtatásban.
10: BEFORE_PROG Fejlec() // A fejlécet nyomtató eljárás
11: {
12: // szöveg nyomtatása a lista tetejére
13: CPRINT( "Listás halmaz nyomtatás:\n" );
14: // '\n' karakterpár = soremelés: hogy az
15: // első rekord nyomtyatása is a sor
16: // elején kezdődjön
17: }
4. ábra
REKLISTA.TOP program - 'Fejlec' eljárás
A Rekord_nyomtatas eljárás a 19-34. sorig tart (5. ábra). Elsőként SZAMLALO-nak (21. sor), annak a számnak a növelése történik eggyel, amely a halmaz rekordjait számolja. A program 7. sora írja le, hogy mit is kell értenünk pontosan SZAMLALO néven: egy egész szám, 0 alapértékkel. A 22. sorban történik a SZAMLALO értékének kinyomtatása a sorok elejére az NPRINT rendszer eljárás segítségével. A függvény paraméteri sorrendben: egy, a szám elé nyomtatandó (macskakörmök közötti) szöveg - "" ('üres' szöveg), mivel nem kell semmit nyomtatni; a nyomtatandó szám - SZAMLALO; mezőszélesség, amelyben a számot balra rendezve nyomtatni kell - 4; a szám után nyomtatandó szöveg - ". ". Ezután jön a rekord azonosítójának nyomtatása (24. sor) a DREFPRINT fügvénnyel. Az eljárás paramétere CURRDREF, az aktuális (éppen nyomtatott) találati halmaz rekord azonosítója. A 26. sorban a TABTO függvénnyel pozícionálás történik a 15 oszlopra ( az oszlop sorszáma a függvény paramétere ), hogy a rekord adatok kiírása egymás alá rendezve jelenjen meg a listában. A PRINT eljárással a találati halmazz rekord egy tetszőleges mezejét lehet kiirattatni. Ez történik a 29. sorban. Az első paraméter a mező elé kinyomtatandó szöveg - ez most ": " elválasztó jelek; a következő a mező sorszáma vagy neve - ##FOMEZO; és az utolsó a mező után kiirandó szöveg - ebben az esetben ez "\n", tehát új sorban folytatódik a nyomtatás majd. A ##FOMEZO egy olyan speciális mezőnév, amely a rekord típusától függetlenül, a főmezőt jelenti, vagyis a rekordot leginkább jellemző mezőt. Pl. a DOKUMENTUM típusú rekordokban a főmező a FOCIM mező (könyv legjellemzőbb adata a címe), a PELDANY-ban a VONALKOD (a könyv példánynak a példány vonalkódja), az ALKOTO-ban a NEV (a szerzőnek a neve) stb. (A rekordok és mezőik neveiről a DBSTRUCT.EXE programmal kaphatunk felvilágosítást.)
19: PROG Rekord_nyomtatas() // A rekordokat nyomtató eljárás
20: {
21: SZAMLALO = SZAMLALO+1; // a rekord számláló növelése 1-gyel
22: NPRINT( "",SZAMLALO,4,". " ); // a sorszám kinyomtatása: 4 betű
23: // szélességben és utána '.' és ' '
24: DREFPRINT( CURRDREF ); // az éppen nyomtatott rekord
25: // azonosítójának a nyomtatása
26: TABTO( 15 ); // pozicionálás a 15. oszlopig,
27: // hogy a kiírások egymás alatt,
28: // rendezetten kezdődjenek
29: PRINT( ": ",##FOMEZO,"\n" ); // a rekord főmezejének, a rekordot
30: // leginkább jellemző mező
31: // tartalmának kinyomtatása
32: // '\n' = soremelés: hogy a következő
33: // kiírás új sorba kerüljön
34: }
5. ábra
REKLISTA.TOP program - 'Rekord_nyomtatas' eljárás
A Lablec eljárás egyetlen NPRINT eljárás segítségével oldja meg a lista zárósórának kiírását (6. ábra), a SZAMLALO szövegbe ágyazott kinyomtatását. A 0 mező szélesség megadása természetesen értelmetlen, az a jelentése, hogy a számot olyan szélességben kell majd nyomtatni ahány számjegyből áll éppen.
36: AFTER_PROG Lablec() // A lista zárósorát nyomtató eljárás
37: {
38: // a lista végén a halmazban lévő rekordok számának kiírása:
39: // darabszám előtti szöveg; a rekordok száma (0, azaz) a szám
40: // méretének megfelelő hosszban; számláló utáni szöveg
41: NPRINT( "A halmazban ",SZAMLALO,0," db rekord volt.\n" );
42: }
6. ábra
REKLISTA.TOP program - 'Fejlec' eljárás
A REKLISTA.TOP program a \TEXTLIB\PRINTER\ könyvtárban található. További példák találhatók ebben a könyvtárban a nyomtató nyelvi programozásra: THULPRN.TOP (,a TH_LPRN.TLM modul nyomtató nyelven meírt változata) - a REKLISTA.TOP-nál árnyaltabb, elsősorban könyv és példány rekordok nyomtatására szolgáló, lista szerű nyomtatási forma; CEDULA.TOP - egy egyszerűsített cédula formátum.
A REKLISTA.TOP programból az OUTCOMP.EXE fordító programmal készíthetünk modult. Lépjünk be a \TEXTLIB\PRINTER\ könyvtárba (REKLISTA.TOP és OUTCOMP.EXE is itt található) és indítsuk el a fordító programot a 7. ábra szerint.
C:\>CD \TEXTLIB\PRINTER C:\TEXTLIB\PRINTER>OUTCOMP REKLISTA.TOP 7. ábra REKLISTA.TOP lefordítása
Az indítás után a képernyőn a 8. ábrát látjuk majd. Az első sorban a fordító önmagáról ír ki információt, a másodikban a fordított program nevét, majd a fordítás befejeztét jelzi és végül a létrehozott modul nevét a könyvtár névvel együtt. A REKLISTA.TOP programból tehát REKLISTA.TLM nevű modul készül, és ugyanoda kerül, ahol a többi textlib modul van, a \TEXTLIB\TLM\ könyvtárba.
OUTCOMP V1.0 - TextLib nyomtató nyelvi fordító InfoKer 1997 reklista.out: Fordítás rendben ! Generált module: \TEXTLIB\TLM\reklista.TLM 8. ábra OUTCOMP.EXE kiírásai REKLISTA.TOP fordítása közben
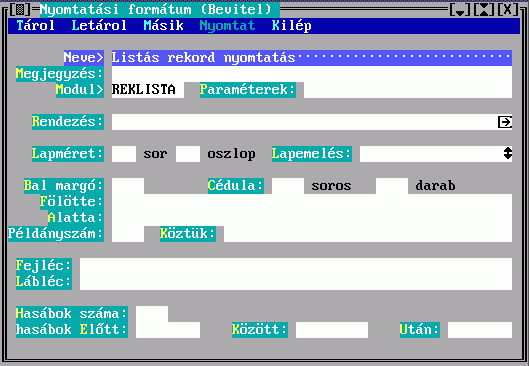
Lépjünk be a TextLibbe rendszergazdaként és a 'Rendszer/ rendszerelemek Bevitele/Nyomtatási formátum' menüpontokon keresztül hívjuk elő a Nyomtatási formátum beviteli űrlapját (9. ábra). Két mezőt kell kitöltenünk: 'Neve', 'Modul'. Az ábra szerinti kitöltéssel a formátum tárolása után a TextLibben bárki elérheti az új nyomtatási módot 'Listás rekord nyomtatás' néven.
A Mező specifikációt egyelőre még csak a statisztikai szempontok megadásánál használjuk, de elképzelhető, hogy máshol is jól fog még jönni.
Ez igazából egy olyan lehetőség, ami egy rekord egy mezőjének értékét adja meg. Megadható több mező is, hogy ha az egyik nincs kitöltve, akkor a másik értékét használja a program (pl: FOCIM, PARHCADAT, CIMADAT). A mező azonban nem kell, hogy a rekord része legyen, lehet egy hivatkozott rekordban levő mező is (pl: példány kötetének ETO jelzete).
A mező definiálása a következő adatlapon történik (ami a statisztika szempont definiálásából érhető el):
A Neve mezőben egy az asszociált mezőre jellemző nevet kell megadni (a nyelv szerinti statisztikánál pl. célszerűen "Nyelv"-et). A Mező mezőben azokat a mezősorszámokat (valódi mezősorszámok, a DBSTRUCT programból deríthetők ki) kell megadni, amelyek bármelyike megfelel a szöveges Neve mezőben megadott értelmezésnek és amelyek közül az első kitöltött mezőt veszi majd a kiértékeléskor alapul a program.
Példánkban a nyelv mező nem a példány rekordban, hanem a példány által hivatkozott kötet rekordban van, tehát ennek a hivatkozó mezőnek a sorszámát (63) kell egyedüli lehetőségként megadni (a hivatkozott kötet rekordnál viszont maga a nyelv mező, de - mivel a többkötetes dokumentumoknál esetleg csak a közös adatnál van megadva a nyelv - a közös adatra hivatkozó mező is, tehát két mező adandó meg).
A Mező-ben zérus érték is megadható; ez a kérdéses rekord adatfile-ját jelenti. Erre a lehetőségre pélául a dokumentumtípus szerinti osztályozásnál van szükség.
Ha a mezők bármelyike másik rekordra hivatkozó mező, a Hivatkozott mező aktív; ha itt beszúrás-t választunk, a hivatkozott rekord megfelelő mezőjét adhatjuk meg a fentivel azonos formátumban. Ha a hivatkozás többféle rekordra lehetséges, a Hivatkozott mezőben ennek megfelelő számú előfordulás adható meg (a hivatkozási helyeket a hivatkozott rekord adatfile-jának vagy rekordtípusának megadásával azonosíthatjuk). A hivatkozott rekord megadott mezője szintén lehet hivatkozó mező, tehát tetszőleges, a példány rekordból akárhány hivatkozáson keresztül elérhető adatbázismező megadható a szemponthoz asszociált mezőként.
Ha bármely szinten egy hivatkozó mező esetén nem töltjük ki a Hivatkozott mezőt, a hivatkozott rekord ún. főmezőjének (általában a rekordok legjellemzőbb mezőjének) értéke lesz a kérdéses szempont szerinti osztályozásnál a besorolás alapja. A szállító szerinti statisztikánál pl. nem kell megadni a Hivatkozott mezőt, hiszen a hivatkozott cég-rekordnak főmezője a cég neve, ami éppen megfelel. A nyelv szerinti statisztikánál viszont két előfordulást is fel kell vennünk a Hivatkozott mezőbe annak megfelelően, hogy a példány kötete vagy kötet-rekordra vagy - az időszaki kiadványoknál - időszaki szám rekordra hivatkozhat és ezek egyikének sem főmezője maga a nyelv, tehát a főmezős feloldás nem megfelelő.
A Max hossz mezőben azt adhatjuk meg, hogy milyen hosszban vegye figyelembe a program a kapott értéket. Pl: kiadási évnél ezt célszerű 4-re venni, hogy az "1979-" ne külön érték legyen, hanem az "1979"-cel megegyező.
A Határoló mezőben megadhatunk olyan karaktereket, amiket ki kell hagyni. Az előbb említett problémát pl. úgy is meg lehet oldani, hogy a "-" jelet határoló jelnek vesszük fel.
Ha a statisztika szempont definiálásánál az Értékek Száma ismert, a kérdéses szempont esetén értelmezett éRtékkészlet mező megadására az alábbi formátum szolgál:
Az Érték Neve mezőben a kérdéses szempont egy értékének az azonosítóját kell megadni (az itt megadott érték fog szerepelni a kérdéses szempont szerinti statisztika fejlécében, tehát pl. ha a dokumentumtípus szempont egyes értékei: könyv, időszaki, hanghordozó, stb.
A Kiértékelési rangszám mezőt akkor kell kitölteni, ha nem mindegy, hogy az értékkészlet elemeit milyen sorrendben próbálja "illeszteni" kiértékeléskor a program. Azoknak az elemeknek a kiértékelése történik meg előbb, amelyeknél itt megadunk egy számot, méghozzá a megadott számok emelkedő sorrendjében, és csak ez után kerül sor az értékkészlet egyéb elemeinek kiértékelésére (ezek sorrendje megegyezik a felsorolás sorrendjével). Használatára pl. a tartalom fő jellege szempontnál kerülhet sor, ugyanis előbb kell eldönteni, hogy gyermekirodalom-e valami és csak utána azt, hogy szakirodalom (ami egyiknek sem minősül, az a szépirodalom). Általánosságban tehát olyankor kell ezt a mezőt megadni, amikor a szempontok egyes értékeinek megadási sorrendje és a szükséges kiértékelési sorrend eltér. Elvben felmerül, hogy a megadás megfelelő sorrendjével el lehetne érni a megfelelő kiértékelési sorrendet, azonban a megadási sorrend az eredménytáblázat oszlopainak sorrendje is egyben; ha ez valamilyen oknál fogva - akár csak a megszokás okán - kötött, a kiértékelési rangszámot kell használni.
Az Értéke mezőt akkor kell megadni, ha a kérdéses értékkészlet-elem nem bontandó tovább (pl. a tartalom fő jellege, mint szempont szerinti osztályozás "gyermekirodalom" értéke nem bontandó tovább, tehát az ÉRtéke mező megadása révén kell rendelkezni arról, hogy milyen mező milyen értékei esetén minősül egy dokumentum gyermekirodalomnak.
Az ÉRtéke mező ismételhető; az ismétlődések egymással VAGY kapcsolatban értelmezendők. Az ismétlődések mindegyike mezőérték párokat definiál (lásd alább). Az értékkészlet kérdéses eleme akkor "illeszthető" egy példány-rekordra, ha valamelyik mező a hozzá tartozó értéket tartalmazza.
Például gyermekirodalomnak akkor minősül egy dokumentum, ha az ETO főtáblázati eleme 087.5 vagy formai alosztása 02.053.2 illetve 02.053.6; ennek megfelelően annál az értékkészlet-elemnél, ahol a Neve mezőben "Gyermekirodalom" szerepel, az ÉRtéke mezőnek két előfordulása lesz, melyek közül az elsőnél a mező az ETO főtáblázati elemét, az érték a 087.5 értéket, míg a másodiknál a mező az ETO formai alosztását, az érték két ismétlődést, a 02.053.2 és 02.053.6 értékeket tartalmazza.
Ha az ÉRtéke mezőt megadjuk, a csak a hierarchikus tovább osztályozásnál értelmezett ÉrtékKészlet és ÖSszegzés mezők láthatatlanná válnak.
Ha szükség van hierarchikus tovább-osztályozásra, az ÉrtékKészlet mezőben lehet megadni a további bontást (ugyanilyen formátum alkalmazásával). Ilyen eset fordul elő a tartalom fő jellege szempont szerinti osztályozásnál: az első szinten az értékkészletnek 3 eleme van (szakirodalom, szépirodalom és gyermekirodalom, melyek közül a szakirodalom tovább bomlik szakjelzet szerint különböző szakterületekre). Arról, hogy az alárendelt osztályozás szerinti statisztikai értékek "Összesen"-jét kell-e képezni és nyomtatni a statisztika készítésekor, az ÖSszegzés mező megfelelő beállításával lehet rendelkezni.
Az ÉRtéke mező megadása az alábi formátum alkalmazásával történik:
A Mező specifikációja a szempont definiálásánál már ismertetett módon impleir.txt történik.
Az ÉRték (ismételhető) mezőben a Mező-ben specifikált mező elfogadható értékeit kell megadni. A megadásnál használható a csonkolás és az intervallum jele.
Páldák: imppld.txt
Páldák: exppld.txt
A program igen sokféle hibát tud jelezni. A talált hibákat a DBCHK.LOG állományba írja. A hibakódok jelentései (a sor elején * jelzi, ha a //javit opcióval a hiba javítható):
| Hibaüzenet | Jelentése |
|---|---|
| 95.01.01 előtti dátum | dátum mezőben túl kis érték |
| cimek | a FOCIM, PARHCADAT, CIMADAT ellentmondásban |
| dupla | egy almező duplán szerepel a rekordban |
| egész érték -1 | Szám típusú mezőben -1 érték szerepel |
| hivatkozás | rossz érték a hivatkozó mezőben |
| közöse | kötet közös adata nincs kitöltve, pedig van részjelzése |
| mai napnál újabb | Dátum mezőben mainál nagyobb dátum |
| nincs címe | Nincs címe |
| nincs kötete | példánynak nincs kitöltve a KOTETE mezője |
| pld. kötete nem vissza | példány kötete nem mutat vissza |
| dok. kötete nem vissza | közös adat kötete nem mutat vissza |
| részjel | kötet RESZJELZES-e nincs kitöltve, pedig van közös adata |
| rossz rekord | sérült rekord szerkezet |
| SPACE kezdet | String mező SPACE-szel kezdődik |
| SPACE vég | String mező SPACE-szel végződik |
| több SPACE | String mezőben több SPACE egymás után |
| törölt rekord | Kapcsolódó mezőben nem létező rekordra hivatkozás |
| üres mező | Ismételhető mezőben üres mezőelőfordulás |
| üres rek | A rekordnak minden (nem rendszer) mezője üres |
| üres pld | A példánynak minden fontos mezője üres. Ezek: vonalkod, leltariszam, kotete, rakt.jelzet, allomany, raktar |
| újdonság | A kötet nem került be az újdonságok közé |
| kölcs (10) | KOLCS rekordban a VISSZAhozás dátuma és KOV_FELSZOLITAS is ki van töltve |
| kölcs (11) | KOLCS rekordban a VISSZAhozás dátuma és a KOLCSONZO is ki van töltve |
| kölcs (12) | KOLCS rekordban a VISSZAhozás dátuma és a KOLCSONOZVE is ki van töltve |
| kölcs (21) | KOLCS rekordban a KIVIVE (kölcsönzés dátuma) mező üres |
| kölcs (22) | KOLCS rekordban a HATARIDO mező üres |
| kölcs (23) | KOLCS rekordban a KIADTA mező üres |
| kölcs (24) | KOLCS rekordban a KOLCSONZOTT mező üres |
| kölcs (31) | KOLCS rekordban van KOLCSONZO, és KOLCSONZO != KOLCSONOZTE |
| kölcs (32) | KOLCS rekordban van KOLCSONOZVE kitöltött és KOLCSONOZVE != KOLCSONOZOTT |
| kölcs (41) | "élő" KOLCS rekordban (VISSZAhozás dátuma üres) a KOLCSONZO (ennek hiányában a KOLCSONOZTE) mező által mutatott olvasó rekordjában nincs bejegyezve a KOLCS rekord, pedig KOLCSONOZVE létező példányra mutat, ugyanakkor lezárt késés- típusú tartozás sem tartozik KOLCS rekordhoz (azaz valószínű hogy még kölcsönözve van, csak az olvasónál nincs bejegyezve) |
| kölcs (42) | "élő" KOLCS rekordban (VISSZAhozás dátuma üres) a KOLCSONZO (ha ez üres, a KOLCSONOZTE) mező által mutatott USER nem olvasható |
| kölcs (43) | KOLCS rekord a KOLCSONOZVE mezője által hivatkozott PELDANY nem mutat vissza KOLCS mezőjén keresztül KOLCS rekordra |
| kölcs (44) | KOLCS rekordban a KOLCSONOZVE mező által mutatott PELDANY nem olvasható |
| kölcs (45) | "élő" KOLCS rekordban (VISSZAhozás dátuma üres) a mind a KOLCSONZO, mind a KOLCSONOZTE mező üres |
| kölcs (46) | "élő" KOLCS rekordban (VISSZAhozás dátuma üres) a KOLCSONZO (ennek hiányában a KOLCSONOZTE) mező által mutatott olvasó rekordjában nincs bejegyezve a KOLCS rekord, ugyanakkor KOLCSONOZVE mező üres vagy az általa mutatott PELDANY nem olvasható |
| kölcs (47) | "élő" KOLCS rekordban (VISSZAhozás dátuma üres) a KOLCSONZO (vagy KOLCSONOZTE) mező által mutatott olvasónál be van jegyezve a KOLCS rekord, ugyanakkor KOLCSONOZVE mező üres |
| kölcs (48) | "élő" KOLCS rekordban (VISSZAhozás dátuma üres) a KOLCSONZO (vagy KOLCSONOZTE) mező által mutatott olvasónál be van jegyezve a KOLCS rekord, ugyanakkor KOLCSONOZVE mező által mutatott PELDANY nem olvasható |
| kölcs (49) | "élő" KOLCS rekordban (VISSZAhozás dátuma üres) a KOLCSONZO (ennek hiányában a KOLCSONOZTE) mező által mutatott olvasó rekordjában nincs bejegyezve a KOLCS rekord, pedig KOLCSONOZVE létező példányra mutat, ugyanakkor a hozzá tartozó késés-típusú TARTOZAS státusza lezárt (azaz valószínű, hogy vissza lett véve) |
| kölcs (50) | (valószínűleg) kölcsönzött példánynál a KOLCSONZO mező nincs kitöltve (KOLCSONOZTE alapján a program kitölti) |
| kölcs (51) | kölcsönzött példánynál a KOLCSONZO mező üres (KOLCSONOZTE mező alapján a program kitölti) |
| kölcs (251) | KOLCS rekordban a KOLCSONOZTE mező üres |
| kölcs (252) | KOLCS rekordban a HOSSZABITVA > HOSSZ_DB |
| kölcs (253) | KOLCS rekordban a FELSZOLITANDO mező nem üres |
| kölcs (261) | KOLCS rekordban a HATARIDO <= KIVIVE |
| kölcs (262) | KOLCS rekordban a VISSZA < KIVIVE |
| kölcs (263) | KOLCS rekordban van felszoltas, es MaiNap < HATARIDO |
| kölcs (811) | PELDANY rekord KOLCS mezője által hivatkozott KOLCS rekordnak a KOLCSONOZVE mezője üres |
| kölcs (812) | PELDANY rekord KOLCS mezőjéből hivatkozott KOLCS rekordnak a KOLCSONOZVE mezője nem erre a PELDANY rekordra mutat vissza |
| kölcs (813) | PELDANY rekord KOLCS mezőjéből hivatkozott rekord nem olvasható |
| kölcs (814) | PELDANY rekord KOLCS mezőjéből hivatkozott ELOJEGY rekord KIJELOLVE mezője nem mutat vissza erre a PELDANY rekordra |
| kölcs (815) | PELDANY rekord KOLCS mezőjéből hivatkozott KKOLCS rekordnak a KOLCSONOZVE mezője üres |
| kölcs (816) | PELDANY rekord KOLCS mezőjéből hivatkozott KKOLCS rekordnak a KOLCSONOZVE mezője nem erre a PELDANYra mutat |
| kölcs (899) | PELDANY rekord KOLCS mezője nem a megfelelő típusú rekordok (KOLCS, ELOJEGY, KKOLCS) valamelyikére mutat |
| kölcs (911) | Olvasó valamelyik U_STAT-almezője KOLCSONZESEK mezője által hivatkozott valamelyik KOLCS rekord nem olvasható |
| kölcs (912) | Olvasó valamelyik U_STAT-almezője KOLCSONZESEK mezője által hivatkozott valamelyik KOLCS rekord KOLCSONZO mezője üres |
| kölcs (913) | Olvasó valamelyik U_STAT-almezője KOLCSONZESEK mezője által hivatkozott valamelyik KOLCS rekord KOLCSONZO mezője másik olvasóra mutat |
| kölcs (914) | Olvasó valamelyik U_STAT-almezője KOLCSONZESEK mezője által hivatkozott valamelyik KOLCS rekord már nem "élő" kölcsözést fed (VISSZAhozás dátuma mező ki van töltve ill. KOLCSONOZVE mező üres) |
| kölcs tartozás (61) | KOLCS rekord KESES_TARTOZAS mezője által mutatott TARTOZAS rekord nem olvasható |
| kölcs tartozás (62) | lezárt kölcsönzésnél (VISSZAhozás dátuma kitöltve) KOLCS rekord KESES_TARTOZAS mezője által mutatott TARTOZAS rekordban a tartozás összege zérus |
| kölcs tartozás (63) | KOLCS rekord KESES_TARTOZAS mezője által mutatott TARTOZAS rekordban a tartozás összege negatív (az ELVESZT_TARTOZAS mező ki van töltve - vélelmezett elvesztés) |
| kölcs tartozás (64) | KOLCS rekord KESES_TARTOZAS mezője által mutatott TARTOZAS rekordban a tartozás összege negatív, pedig ELVESZT_TARTOZAS üres (nincs vélelmezett elvesztés) |
| kölcs tartozás (65) | "élő" KOLCS rekordban (VISSZAhozás dátuma üres, KOLCSONZO-nél a kölcsönzések között be van jegyezve) a KESES_TARTOZAS mező által mutatott TARTOZAS rekord MIERT mezője üres |
| kölcs tartozás (66) | "élő" KOLCS rekordban (VISSZAhozás dátuma üres, KOLCSONZO-nél a kölcsönzések között be van jegyezve) a KESES_TARTOZAS mező által mutatott TARTOZAS rekord MIERT mezője által mutatott PELDANY nem olvasható |
| kölcs tartozás (67) | KOLCS rekord KESES_TARTOZAS mezője által mutatott TARTOZAS rekordban mind az UGYFEL mind a KI mező üres (csak //javit paraméter esetén jelzi a hibát, amikor azonnal javítja is!) |
| kölcs tartozás (68) | KOLCS rekord KESES_TARTOZAS mezője által hivatkozott TARTOZAS rekord javíthatatlan hiba - 511, 512, 532, 533, 534, 553 - miatt törlésre kerül, ezért a KOLCS rekordból is törölni kell a KESES_TARTOZAS mezőt (csak //javit paraméter esetén fordul elő, és akkor el is végzi a törlést) |
| kölcs tartozás (69) | élő KOLCS rekord ELVESZT_TARTOZAS és KOV_FELSZOLITAS mezője egyszerre üres (//javit paraméter esetén a KOV_FELSZOLITAS mezőt tölti ki a program, ha még nem ment utolsó felszólítás, ellenkező esetben elvesztés tartozás rekordot hoz létre a KOLCS rekordhoz) |
| kölcs tartozás (70) | Perelt térítési díj típusú tartozásban érintett PELDANY rekordban mind a STATUSZ mind a SELEJTINDOKA mező üres |
| kölcs tartozás (522) | KOLCS rekord KESES_TARTOZAS mezője által hivatkozott tartozás rekordban a MIERT mező üres (csak //javit paraméter esetén fordul elő, akkor viszont - feltéve hogy a KOLCS rekord KOLCSONZOTT és KOLCSONOZVE mezői valamelyike meg van adva és az általa mutatott PELDANY olvasható - rögtön javítja is arra) |
| kölcs tartozás (523) | KOLCS rekord KESES_TARTOZAS mezője által hivatkozott tartozás rekordban a MIERT mező által mutatott PELDANY nem olvasható (csak //javit paraméter esetén fordul elő, akkor viszont - feltéve hogy a KOLCS rekord KOLCSONZOTT és KOLCSONOZVE mezői valamelyike meg van adva és az általa mutatott PELDANY olvasható - rögtön javítja is arra) |
| tartozás (510) | rendezetlen TARTOZAS (RENDEZES_MODJA mező üres) rekordban a KI mező által mutatott USER nem olvasható |
| tartozás (511) | rendezetlen TARTOZAS (RENDEZES_MODJA mező üres) rekordban a KI mező üres |
| tartozás (512) | rendezetlen TARTOZAS (RENDEZES_MODJA mező üres) rekord KI (vagy UGYFEL) mezője által mutatott olvasónál nincs bejegyezve semelyik U_STAT almező TARTOZASOK mezője egyik előfordulásában sem a kérdéses TARTOZAS |
| tartozás (513) | rendezetlen TARTOZAS (RENDEZES_MODJA mező üres) rekordban ki van töltve a BESZEDTE mező |
| tartozás (514) | rendezetlen TARTOZAS (RENDEZES_MODJA mező üres) rekordban ki van töltve a KIEGYENLITVE mező |
| tartozás (515) | rendezett TARTOZAS (RENDEZES_MODJA mező kitöltve) rekordban a KI mező ki van töltve |
| tartozás (516) | rendezett TARTOZAS (RENDEZES_MODJA mező kitöltve) rekord KI (vagy UGYFEL) mezője által mutatott olvasónál be van jegyezve valamelyik U_STAT almező valamelyik TARTOZASOK mezőelőfordulásaként a kérdéses TARTOZAS |
| tartozás (517) | rendezett TARTOZAS (RENDEZES_MODJA mező kitöltve és az nem VISSZASZOLGALTATAS) rekordban BESZEDTE mező üres |
| tartozás (518) | rendezett TARTOZAS (RENDEZES_MODJA mező kitöltve) rekord KIEGYENLITVE mezője üres |
| tartozás (519) | TARTOZAS rekordban az UGYFEL mező üres, pedig a KI mező létező rekordra mutat |
| tartozás (520) | TARTOZAS rekordban mind az UGYFEL, mind a KI mező ki van töltve, de nem ugyanarra a rekordra mutatnak |
| tartozás (521) | TARTOZAS rekordban TARTOK mező üres |
| tartozás (522) | Késés vagy elvesztés miatti TARTOZAS rekordban a MIERT mező üres |
| tartozás (523) | Késés vagy elvesztés miatti TARTOZAS rekordban a MIERT mezőben hivatkozott PELDANY nem olvasható |
| tartozas (524) | Nem késés vagy elvesztés miatti TARTOZAS rekordban a MIERT mező ki van töltve |
| tartozas (525) | Rendezett TARTOZAS rekordban a KOV_FELSZOLITAS mező ki van töltve |
| tartozás (531) | Késés miatti TARTOZAS rekordban TART_STATUSZ üres |
| tartozás (532) | Késés miatti TARTOZAS rekordban TART_STATUSZ VALTOZHAT, de a KI (ennek hiányában az UGYFEL) mező által hivatkozott olvasó semelyik U_STAT-almezője TARTOZASOK mezőjének egyetlen előfordulása sem hivatkozik a rekordra |
| tartozás (533) | Késés miatti TARTOZAS rekordban OSSZEG negatív |
| tartozás (534) | Késés miatti TARTOZAS rekordban OSSZEG zérus, ugyanakkor a KI (ennek hiányában az UGYFEL) mező által hivatkozott olvasó semelyik U_STAT-almezőjének TARTOZASOK mezőjének egyetlen előfordulása sem hivatkozik a rekordra vagy TART_STATUSZ LEZART |
| tartozás (535) | Nem késés miatti TARTOZAS rekordban TART_STATUSZ értéke VALTOZHAT |
| tartozás (541) | Elvesztés miatti TARTOZAS rekordban OSSZEG nem zérus, MEGALLAPITVA ki van töltve, ugyanakkor ELVESZETT nem üres (pedig csak az összeg megállapításáig lehetne kitöltve) |
| tartozás (542) | Elvesztés miatti TARTOZAS rekordban ELVESZETT ki van töltve, MEGALLAPITVA üres (kártérítés megállapítása folyamatban?), ugyanakkor OSSZEG nem zérus |
| tartozás (543) | Elvesztés miatti TARTOZAS rekordban ELVESZETT ki van töltve (kártérítés megállapítása folyamatban?), ugyanakkor a KI (ennek hiányában az UGYFEL) mező által mutatott olvasó semelyik U_STAT-almezőjének TARTOZASOK mezőjének egyetlen előfordulása sem hivatkozik a TARTOZAS rekordra (//javit paraméter esetén - amennyiben az 512-es hibával együtt jelentkezik annak javításával ez is megszűnik, ellenkező esetben - rendezett tartozásnál az ELVESZETT mező törlődik) |
| tartozás (544) | Elvesztés miatti TARTOZAS rekordban ELVESZETT üres, MEGALLAPITVA kitöltve (kártérítés megállapítva), ugyanakkor OSSZEG mező üres |
| tartozás (545) | Elvesztés miatti TARTOZAS rekordban ELVESZETT üres (kártérítés megállapítva?), ugyanakkor MEGALLAPITVA és OSSZEG mező is üres |
| tartozás (551) | TARTOZAS rekordban MIKOR mező üres (pedig nem vélelmezett elvesztésről van szó) |
| tartozás (552) | Késés miatti TARTOZAS rekordban MEDDIG üres |
| tartozás (553) | Késés miatti TARTOZAS rekordban MIKOR > MEDDIG |
| tartozás (554) | Késés miatti TARTOZAS rekordban KIEGYENLITVE és MEDDIG kitöltve, KIEGYENLITVE < MEDDIG |
| tartozás (555) | TARTOZAS rekordban KIEGYENLITVE < MIKOR |
| tartozás (556) | Késés miatti TARTOZAS rekordban MIKOR, MEDDIG, OSSZEG és KESES_SZORZO közötti összefüggés nem teljesül, ami MIKOR vagy MEDDIG hibás voltára utal (//javit paraméter esetén MIKOR és MEDDIG közül azt javítja a program, amelyik irreális; ha mindkettő reális, MEDDIG értékét módosítja a program) |
| tartozás (561) | TARTOZAS rekordban FELSZOLITANDO nem üres |
| selejtez (600) | TORL_JEGYZEK rekord olyan PELDANY rekordra hivatkozik, ami nincs selejtezve |
| selejtez (601) | TORL_JEGYZEK rekord olyan PELDANY rekordra hivatkozik, ami kölcsönözve van (nem lezárt jegyzéknél javítható) |
| user tartozás (71) | az olvasó rekord valamelyik U_STAT-almezőjében a TARTOZIK mező értéke és a TARTOZASOK előfordulásai által reprezentált (rendezetlen) tartozások összege nem azonos |
| user tartozás (711) | olvasó rekord valamelyik U_STAT-almezője TARTOZASOK mezőjének valamelyik előfordulása által hivatkozott TARTOZAS rekord nem olvasható |
| user tartozás (712) | olvasó rekord valamelyik U_STAT-almezője TARTOZASOK mezőjének valamelyik előfordulása által hivatkozott TARTOZAS rekordban a RENDEZES_MODJA kitöltve (rendezett tartozás) |
| user tartozás (713) | olvasó rekord valamelyik U_STAT-almezője TARTOZASOK mezőjének valamelyik előfordulása által hivatkozott késés-tartozás típusú TARTOZAS rekordban a tartozás összege negatív |
| user tartozás (714) | olvasó rekord valamelyik U_STAT-almezője TARTOZASOK mezőjének valamelyik előfordulása által hivatkozott TARTOZAS rekord zérus OSSZEGű rendezetlen tartozást fed (a RENDEZES_MODJA mező üres) ugyanakkor sem nem a USER-nél bejegyzett KOLCSönzéshez tartozó késés típusú tartozásról, sem nem megállapításra váró térítési díjról van szó |
| user tartozás (715) | olvasó rekord valamelyik U_STAT-almezője TARTOZASOK mezőjének valamelyik előfordulása által hivatkozott TARTOZAS rekordban nincs kitöltve az UGYFEL mező |
| előjegy (795) | Az olvasó rekordja nem hivatkozik az ELOJEGY rekordra, pedig az ELOJEGY rekord szerint az olvasó számára félre van téve a példány |
| előjegy (796) | Az olvasó rekordja nem hivatkozik az ELOJEGY rekordra, holott élő, még kielégítetlen ELOJEGY rekordról van szó |
| előjegy (797) | Az olvasó rekordja által hivatkozott ELOJEGY rekord nem az olvasó rekordjára hivatkozik vissza |
| előjegy (798) | Már kielégített ELOJEGY rekordra hivatkozik az olvasó rekordja |
| előjegy (799) | Már kielégített ELOJEGY rekordban KIELEGITI mező nem üres |
| előjegy (800) | ELOJEGY rekordban ERTESITENDO mező kitöltött, ugyanakkor KIJELOLVE mező üres (legvalószínűbb oka: félretett példányt - Olvasó mezőjének rendszergazda által történt törlése után - valaki másnak adtak ki) |
| előjegy (801) | ELOJEGY rekordban VARJUK mező kitöltött, ugyanakkor KIJELOLVE mező üres, azaz nincs meg a már értesített előjegyző számára félretett példány (legvalószínűbb oka: a példány Olvasó mezőjének rendszergazda által történt törlése után valaki másnak adták ki) |
| előjegy (802) | ELOJEGY rekordban ELOJEGYEZTE mező (ami mindig kitöltött kellene legyen) üres |
| előjegy (803) | ELOJEGY rekordban mind ELOJEGYZO, mind ELOJEGYEZTE mező ki van töltve, de értékük eltér |
| előjegy (804) | ELOJEGY rekordban ERTESITENDO mező ki van töltve, de értéke nem azonos ELOJEGYZO mezővel |
| előjegy (805) | ELOJEGY rekordban ELOJEGYZO mező üres (azaz már nem "él" az előjegyzés), a VARTKOTET mező viszont nem az |
| előjegy (806) | ELOJEGY rekordban a MEGFELEL mező olyan példányra mutat, amely nem kölcsönözhető |
| előjegy (807) | PELDANY rekord EJSOR mezője már kielégített ELOJEGY rekordra hivatkozik |
| előjegy (808) | PELDANY rekord MEGFELEL mezője lezárt ELOJEGY rekordra hivatkozik |
| előjegy (809) | PELDANY rekord ALLOKALT mezője már kielégített ELOJEGY rekordra hivatkozik |
| előjegy (810) | Kielégítetlen ELOJEGY rekordban a KIJELOLVE mező ki van töltve |
| előjegy (817) | PELDANY_EJSOR által hivatkozott előjegyzések előjegyzői között többször szerepel ugyanaz az előjegyző |
| előjegy (818) | PELDANY kölcsönözve vagy kijelölve olyan olvasónak, aki szerepel a PELDANY_EJSOR által hivatkozott előjegyzések előjegyzői között |
| előjegy (819) | olvasó rekordjában olyan előjegyzés rekordra vonatkozó hivatkozás szerepel, amely nem érhető el (törölve van) |
| felszólítás (820) | USER FELSZOLITAS-ai között van olyan, amely csak postaköltség-tartozások megfizetésére vonatkozik |
| felszólítás (821) | USER FELSZOLITAS-ai között van olyan, amely nem hivatkozik a felszólító levél postaköltség típusú tartozás rekordjára |
| felszólítás (822) | USER FELSZOLITAS-ai között van olyan, amely nem létező FELSZOLITAS rekordra hivatkozik |
| felszólítás (823) | USER FELSZOLITAS-ai között van olyan, amelynél a még aktuális tételek száma nem egyezik meg a valóban rendezetlen tételek számával |
| felszólítás (824) | USER FELSZOLITAS-ai között van olyan, amelynek már minden tétele rendezve lett |
| felszólítás (825) | USER FELSZOLITAS-ai nem időrendben követik egymást |
| felszólítás (826) | KOLCS rekordban nagyobb a felszólítások maximális száma nagyobb, mint a tényleges felszólítások száma és a paraméter-rendszerből adódó felszólítások max. számának az összege |
| perlés (830) | VITA/PER rekordban a rendezetlen TARTOZAS-ok között van olyan, amelynek a RENDEZES_MODJA mezője nem üres, (azaz rendezett) |
| perlés (831) | VITA/PER rekordban csupa rendezett TARTOZAS rekordra való hivatkozás van, az ELLENFEL mező mégis ki van töltve |
| perlés (832) | PER rekordban nincs kitöltve a NYOMTATANDO mező és a NYOMTATVA mező is üres |
| perlés (833) | USER rekordban a VITA mező PER rekordra mutat |
| számla (81) | Számláról állományba vett példány BESZERZESIAR mezője nem egyezik az aktuálisan a könyvtár rekord-beli állományérték nyilvántartási beállításából (bruttó/nettó) és a megfelelő számlasor adataiból (egységár, ÁFA-kulcs, árforma) adódó értékkel |
| számla (82) | A számla Összesen, ÁFA ill. Engedmény mezői közül egy vagy több nem egyezik a számlasorokból adódó értékkel |
| számla (83) | A számla Összesen és Fizetendő mezője megegyezik, a Fázis mező értéke mégis "rögzítés alatt" |
| számla (84) | A számla sora által hivatkozott MEGRENDELES rekordban nincs a számlasorhoz tartozó dokumentumra vonatkozó tétel |
| számla (85) | A KONYVTAR rekordban nyilvántartott tárgyévi elköltött keret nem egyezik a tárgyévi számlákból kumulált értékkel |
| számla (86) | A szállító CEG rekordjában nyilvántartott tárgyévi elköltött keret nem egyezik a tárgyévi számlákból kumulált értékkel |
| számla (87) | A szerzeményezési CSOPORT rekordjában nyilvántartott tárgyévi elköltött keret nem egyezik a tárgyévi számlákból kumulált értékkel |
| paraméter (90) | A KONYVTAR rekordból hiányzik a hozzáférési paraméter rekordok címeit tartalmazó SUPERPAR rekord címe (//kolcs paraméter esetén vizsgálja) |
| paraméter (91) | A hozzáférési paraméter rekord címe hiányzik abból a rekordból, amihez tartozik (vagy ez utóbbi nem elérhető) (//kolcs paraméter esetén vizsgálja) |
| paraméter (92) | A hozzáférési paraméter rekord címe hiányzik a hozzáférési rekordok címét tartalmazó SUPERPAR-rekordból (//kolcs paraméter esetén vizsgálja) |
| J000 | Nincs elég memória |
|---|---|
| J001 | Az utolsó naplózott rekord eltér az adatbázisbelitől |
| J002 | Az utolsó naplózott rekordot nem sikerült az adatbázisba tölteni |
| J003 | Hibás típusú napló bejegyzés |
| J004 | Hibás napló bejegyzés |
| J005 | Adatbázis olvasási hiba |
| J006 | A napló hibás, sérült |
| J007 | A naplót nem sikerült lezárni |
| J008 | Az adatbázishoz nem készült még napló |
| J009 | A napló file megnyitási hiba |
| J010 | A napló nem létezik |
| J011 | A napló lezárva, rendben |
| J012 | A naplófile fizikailag sérült |
| J013 | - nincs - |
| J014 | Adatbázis módosítási hiba |
| J015 | A naplókat nem sikerült összegyűjteni |
| J016 | A megadott könyvtárban nincs napló |
| J017 | Különböző adatbázishoz tartozó naplók |
| J018 | Nem az adatbázishoz tartozó naplók |
| J019 | Nincs feldolgozatlan ill. betölthető napló |
| J020 | Nincs meg az első betöltendő napló |
| J021 | Hiányzó napló |
| J022 | Napló hiba: naplóból kimaradt adatbázis módosítás |
| J023 | A naplót nem sikerült megnyitni (nem létezik) |
| J024 | Le nem zárt nap a naplóban |
| J025 | Hibás napló bejegyzés ill. le nem zárt napló |
| J026 | Rossz bejegyzés sorrend a naplóban |
| J027 | Nincs listázható napló |
| J028 | Napló létrehozási hiba |
| J029 | Az aktuális napló már létezik |
| J030 | Az aktuális naplót nem sikerült megnyitni (nem létezik) |
| J031 | Napló file átnevezési hiba |
| J032 | File átnevezési hiba, már létező file |
| J033 | Az aktuális naplót nem sikerült megnyitni |
| J034 | Új adatbázis mentést kell készíteni |
| J035 | Már betöltött napló |
| J036 | Napló olvasási hiba |
| J037 | Napló módosítási hiba |
| J038 | Az aktuális napló nevét nem sikerült visszaállítani |
| J039 | Nem naplózott adatbázis módosítás történt |
| J040 | Hibás, rosszul megadott path |
| J041 | File létrehozási hiba, már létező file |
| J042 | Nem megfelelő napló (rossz paraméterek) |
| J043 | Az aktuális napló túl nagy |
| J044 | Hibás napló ill. napló olvasási hiba |
| J045 | A napló betöltéshez nincs elég hely a diszken |
| J046 | Könyvtár létrehozási hiba |
| J100 | Sikertelen adatbázis megnyitás |
| J101 | Sérült adatbázis |
| J102 | Adatbázis írási hiba |
| J103 | Adatbázis lezárási hiba |
| J104 | Adatbázis mentési (írási) hiba |
| J105 | Sikertelen adatbázis (adatfile) megnyitás |
| J106 | Sikertelen adatbázis (indexfile) megnyitás |
| J107 | Az adatbázis leírást nem sikerült betölteni |
| J108 | Nem összetartozó adatbázis file-ok |
| J109 | Adatbázis lezárva (javítandó adatfile-ok) |
| J110 | Sikertelen adatbázis másolás |
| J111 | Sikertelen adatbázis áthelyezés |
| J112 | Sérült adatbázis, csak hibátlan adatbázisra tölthető napló |
| 2000: Rossz napló bejegyzés |
|---|
| 2001: Rossz napló tipus |
| 2002: Más napló tipus |
| 2003: Rossz napló file |
| 2004: Rossz adatbázis azonosító |
| 2005: Rossz adatbázis kor |
| 2006: Rossz napló azonosító |
| 2007: Napló megnyitási hiba |
| 2008: Napló betöltött |
| 2009: Nincs napló file |
| 2010: Van napló file |
| 2011: Nem lezárt napló |
| 2012: Rossz napló verzió |
| 2013: Uj napló kell |
| 2014: Nagy az aktuális napló |