Duplázódások megszüntetése
Figyelem! Ez a módszer az 1654-es TextLib verziótól kezdve használható.
Korábbi verziókban is van wdbdupl modul, de az nem tudja kezelni az
újabb dbdupl programok által készített fájlokat!
1. Bevezetés
Duplázódásról azoknak a rekordoknak az esetében beszélhetünk, amelyeket jellegüknél fogva egyedinek képzelünk, mert a valóságban nincs belőlük kettő, csak egy. Ilyenek az alkotókat, a testületeket, a rendezvényeket, a földrajzi helyeket, az olvasókat, a személyeket, a sorozatokat leíró rekordok. Lehetnek mások is, ezekre a másokra a duplázódás megszüntetésének lehetősége az itt leírt módszerrel egyelőre nem terjed ki.
Természetesen az élet nem zárja ki két azonos nevű alkotó létét. Ebben a leírásban annak az elkerüléséről is lesz szó, hogy véletlenül két olyan rekordból csináljunk egyet, amelyből valóban kettő van.
Két rekord azonosságának megítéléséhez nem elég egyetlen mezőjük azonosságát vizsgálni. A módszer nem pusztán a nevek vagy címek azonossága alapján dönt, több szabályt alkalmaz annak érdekében, hogy azt minősítse azonosnak, ami valóban nagy valószínűséggel azonos. Az azonosságról szóló végső döntés természetesen könyvtárosi szakértelmet kíván.
Egyszerű eldönteni, hogy akarjunk-e foglalkozni a duplázódás megszüntetésével. Ha a TextLib munkaállomásba lépve a Keresés - Segédállományok - ... úton kiválasztjuk valamelyik adattípust az előbb felsoroltak közül, és a név mezőben az expandot választjuk (F9-et nyomunk), akkor a lista minden eleme előtt láthatjuk előfordulásának számát. Ha mindenhol csak egyes van, akkor nem kell a problémával foglalkozni.
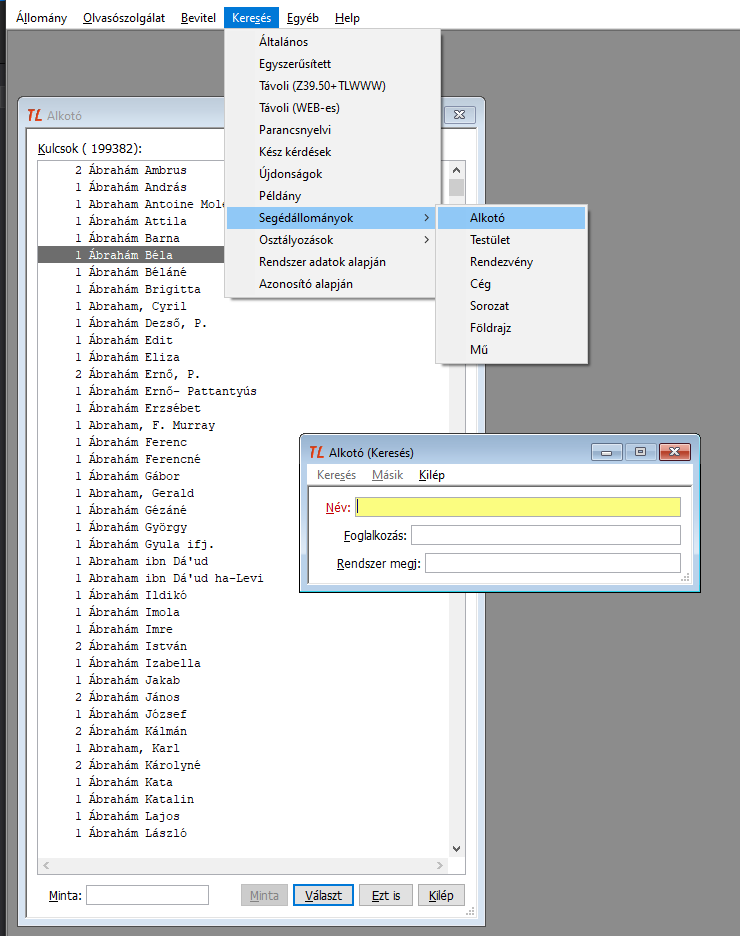
Megjegyzés:
- Pl. alkotó nevek listáját nemcsak a Keresés - Segédállományok - Alkotó úton nyíló ablakban láthatunk, hanem a Keresés - Általános - Szerző mezőből nyitható listában is. Itt azonban a név előtt álló szám a névhez kapcsolt dokumentumok számát jelenti, vagyis azok láttán nem kell aggódnunk a duplázódás jelensége miatt.
2. A duplázódás oka
A TextLibben az önállóan értelmes adategyüttesek - rekordok - leírására minden ilyen adategyüttesnek saját űrlapja van. Így van ez a bevezetőben felsorolt alkotókkal, testületekkel, rendezvényekkel, földrajzi helyekkel, olvasókkal, személyekkel és sorozat címekkel. A program pedig, amikor pl. egy dokumentum bevitelekor a szerző mezőhöz érünk, elsődlegesen azt a lehetőséget kínálja fel, hogy a már korábban bevitt szerzők közül válasszuk a megfelelőt, ne hozzunk létre egy másodikat. Ehhez hasonlóan működik a Hunmarc rekordok importja is, az is arra törekszik, hogy ne jöjjenek létre indokolatlanul duplumok.
A duplázódás oka tehát lehet az, ha a kézzel történő adatbevitelben vagy az importban hiba van.
3. A duplázódás megszüntetésének értelme
Két fontos tényt emelhetünk ki:
- A duplázódás megzavarhatja a keresést
Tekintsük példának a szerző neve alapján zajló keresést. A keresésben a program az azonos neveket összevonja, azt is mondhatnánk tehát, hogy nem számít, ha több Nemere Istvánunk van, a keresés az összes Nemere István művet megtalálja. Viszont Nemere Istvánnak névváltozatai is vannak, és ha a keresést valamelyik névváltozat alapján indítjuk, akkor csak azoknak a Nemere Istvánoknak a műveit fogjuk megtalálni, akiknek az a névváltozata is rögzítve van az űrlapján, amely alapján a keresést indítottuk.
- A duplázódás zavarja az adatbevitelt
Fölösleges időtöltés, amikor több Nemere István közül kell kiválasztanunk a legmegfelelőbbet egy újonnan bevitt könyv szerzőjeként. Egyszerűbb, ha csak egy van.
4. A duplázódás megszüntetésének módszere
A duplázódás megszüntetésének elhatározását nem kell attól függővé tenni, hogy kevés vagy sok duplát találtunk az adatbázisban, a módszer ugyanis döntő részben programok futtatásából áll. Természetesen a könyvtárosi szakismeretet igénylő munka mennyisége függ a duplák számától, de a feladat egészében a programoké a fő szerep.
A módszer három lépésből áll:
- A duplák, triplák stb. megkeresése (dbdupl program - rendszergazda)
- Döntés a megtalált rekordokról (duplikátum szerkesztő - könyvtáros)
- A döntések átvezetése az adatbázisba (drefch program - rendszergazda)
5. A lépések
5.1. A duplák, triplák stb. megkeresése
Ezt a lépést egy parancssori program futtatásával a TextLib szerver gépen intézhetjük. A program neve a windowsos szerveren w-dbdupl.exe, a linuxosén pedig g-dbdupl.exe. (A döntések véglegesítése pontban szükség lesz a w-drefch.exe vagy g-drefch.exe programra is.) Amennyiben nincs meg valamelyik program, töltsük le, és másoljuk a helyére:
- Windows
- 64 bites: "%ProgramFiles(x86)%\TextLib Windows Szerver\exe"
- 32 bites: "%ProgramFiles%\TextLib Windows Szerver\exe"
- Linux: /usr/share/textlib/exe
A dbdupl programot a TextLib szerver program leállítása után indíthatjuk.
- Figyelem! A program szövegfájlokat hoz létre!
Ha a TextLib Szerver mappából indítanánk, akkor a létrehozás nem
biztos, hogy sikerülne. Egyébként se használjuk a program mappákat
ideiglenes fájlok tárolására!
Egy olyan mappából indítsuk, ahova a programnak jogában áll fájlokat írni. Pl. Windowsban a c:\temp mappa, Linuxban a /tmp. Ebben a mappában legyünk, amikor kiadjuk a parancsot:
- Win/64bit: "%ProgramFiles(x86)%\TextLib Windows Szerver\exe\w-dbdupl.exe"
- Win/32bit: "%ProgramFiles%\TextLib Windows Szerver\exe\w-dbdupl.exe"
- Linux: /usr/share/textlib/exe/g-dbdupl.exe
A program percekig fut, az adatbázist nem módosítja, és a végén 7 db .txt fájlt hoz létre (a személyek az olvasók jótállói lehetnek):
- alkoto.txt
- foldrajz.txt
- olvaso.txt
- rendezveny.txt
- sorozat.txt
- szemely.txt
- testulet.txt
A szövegfájlokat nemcsak csoportosan, hanem egyesével is létrehozhatjuk. A parancs - példának a földrajzi neveket választva - így módosul:
- 64 bites: "%ProgramFiles(x86)%\TextLib Windows Szerver\exe\w-dbdupl.exe" /foldrajz
- 32 bites: "%ProgramFiles%\TextLib Windows Szerver\exe\w-dbdupl.exe" /foldrajz
5.1.1. A szövegfájlba kerülés szabályai
A fájlnév.txt-kben felsorolódó nevek vagy címek nem önmagukban állnak, mindegyik egy-egy rekordot képvisel. A rekordokban pedig más mezők is vannak, amelyeknek a tartalma növelheti vagy csökkentheti a valószínűségét annak, hogy az azonos nevekhez vagy címekhez tartozó rekordok valóban azonosak. Ezért a dbdupl program nemcsak a neveket vagy a címeket vizsgálja, hanem a rekordoknak több mezőjét is bevonja. Ezek a mezők rekordpusonként mások, az alábbiak:
- Alkotó rekord: Neve, Évek, Névkiegészítő, Méltóság, Foglalkozás
- Földrajz rekord: Megnevezés, Érvényes, Megye
- Olvasó rekord: Név, Szem.ig, Szül.idő, Szül.hely, Anyja neve, Neme
- Rendezvény rekord: Neve, Sorszám, Székhely, Egységesített neve, Fennállás
- Sorozat rekord: Főcím, Alcím, egyéb címadat, ISSN, ISBN
- Személy rekord: Név, Szem.ig, Szül.idő, Szül.hely, Anyja neve, Neme
- Testület rekord: Neve, Sorszám, Székhely, Egységesített neve, Fennállás
A több mezőre kiterjedő vizsgálat nagy biztonsággal kizárja, hogy különbözőnek szánt rekordokat a dbdupl program a szövegfájlba illessze. Hiszen ha pl. két alkotó rekordban a nevek azonosak is, az Évek mező vizsgálata elég lehet ahhoz, hogy kimaradjon az azonosnak feltételezettek közül.
További apróságok árnyalják a szabályrendszert. A program:
- Figyelmen kívül hagyja az írásjeleket
- Nem tesz különbséget a kis- és nagybetűk között
- Figyelembe veszi a diakritikus jeleket
Megjegyzés:
- A dbdupl program nem tud törődni az elírásokkal. Észre sem veszi, hogy Vörösmarty és Vörösnarty csak egy tévedés miatt van, ez valójában egy duplázódás. A dbdupl szabályrendszere alapján a két rekord nem kerül be a szövegfájlba.
5.2. Döntés a megtalált rekordokról
5.2.1. Bevezetés
A dbdupl program szabályrendszerének értelmezéséből megállapíthatjuk, hogy szövegfájlokba azok a rekordok kerülnek be, amelyek nagy valószínűséggel indokolatlan, téves duplikátumok. A cél az, hogy az azonosak közül csak egy maradjon meg, a többiek pedig tűnjenek el az adatbázisból. A kiválasztás pedig könyvtárosi szakismeretet igénylő feladat, és a szövegállományok részletes átvizsgálása útján teljesül.
Az átvizsgálást a TextLib munkaállomás programba könyvtárosként lépve a wdbdupl modulban végezhetjük. Másoljuk a hét szövegfájlt olyan helyre, ahol a TextLib winkliens meg tudja nyitni, és a változtatások után el is tudja majd menteni.
Megjegyzések:
- Nem muszáj feldolgozni mindent szövegfájt, ez a könyvtár döntése.
- Nem muszáj egyszerre feldolgozni a szövegfájlokat. Nem kötelező a műveletsor harmadik lépését az összes szövegfájllal egyszerre elvégezni.
- A különböző szövegfájlok feldolgozása folyhat egyszerre több TextLib munkaállomáson. De egy szövegfájl egyszerre két gépen semmiképp ne módosítsunk!
- A feldolgozás tarthat sokáig, de közben az adatbázisban nem történhet olyan változás, ami a munkát értelmetlenné vagy érvénytelenné tenné.
5.2.2. A wdbdupl modul
A wdbdupl modult az Egyéb - Eszközök - Modul indítás menüpontban a Modul mezőbe a wdbdupl nevet beírva indíthatjuk el.
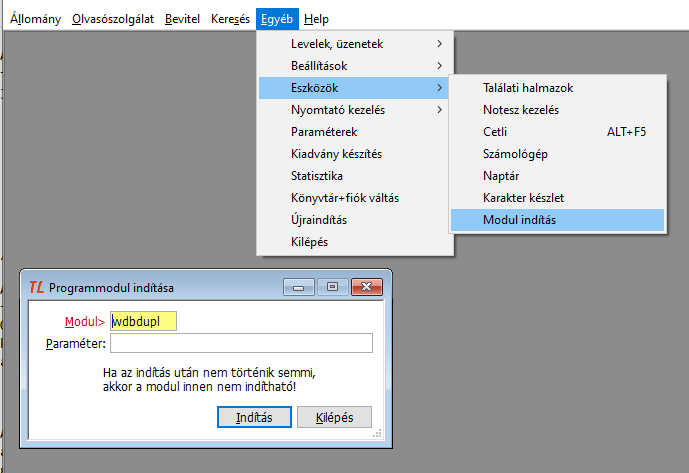
A modul azonnal egy tallózó ablakot mutat a feldolgozandó szövegfájl kiválasztása céljából. A kiválasztás után a duplikátum szerkesztő ablak nyílik meg.
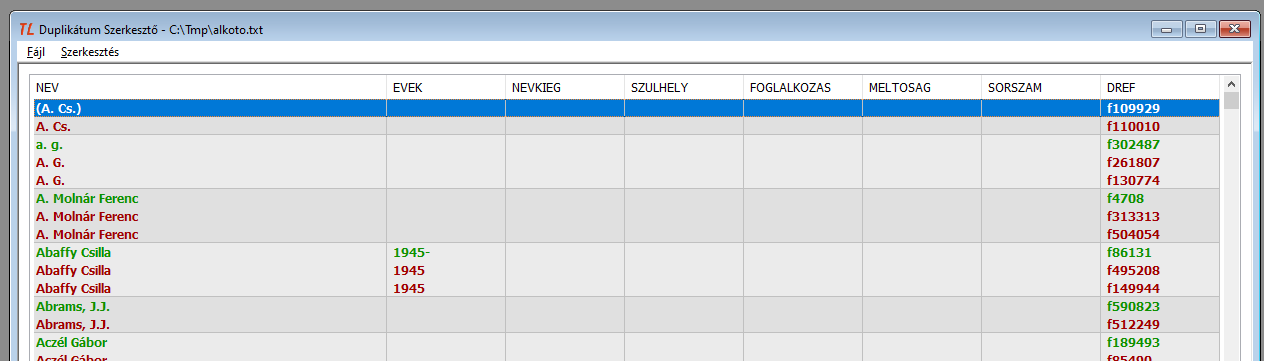
Az ablakban az első megnyitáskor kétféle színű sor látható: zöld és piros. Az azonosnak látszó nevek egy csoportot alkotnak, felváltva világos- és közepesen szürke háttérben. A csoportok elsője mindig zöld, a továbbiak pedig mind pirosak. Ha nem tennénk semmit, akkor a Döntések átvezetése az adatbázisba pont végrehajtása után a zöld sorokat jelentő rekordok megmaradnának, az összes piros pedig törlődne az adatbázisból. A sorok a rekordok típusára jellemző mezőkre tagolódnak.
Az ablak saját menüjének két pontja van, és azoknak alpontjai. A Fájl menüpont alpontjainak jelentése magától értetődő, a Szerkesztés pedig így néz ki:
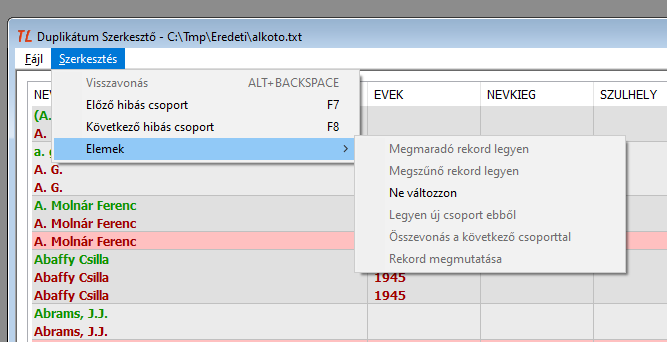
Egy picit halasszuk el ezeknek a pontoknak a magyarázatát, mert egyszerűbb lesz megérteni a szövegfájl elemeivel végezhető műveletek ismertetésekor.
5.2.3. A műveletek
A szövegfájl bármelyik során állva jobb egérgombbal egy menü nyitható, amely felsorolja a duplikátumok megszüntetése érdekében végezhető műveleteket.
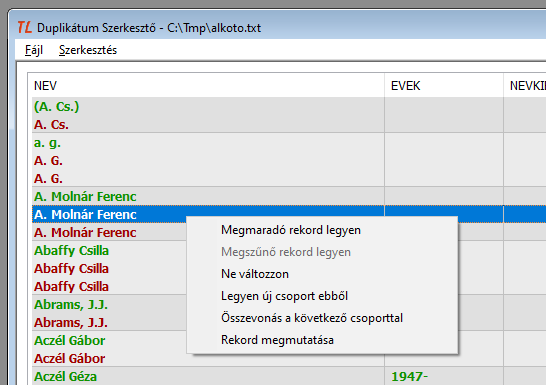
A menüpontok kiválaszthatósága függ attól, hogy az a sor, amin éppen állunk milyen színű, milyen tulajdonságú, emiatt vannak a menüben szürke, nem választható pontok is.
A következő kép jól magyarázza a lehetőségeket, egyben bemutatja a változtatások eredményeként keletkező új színeket.
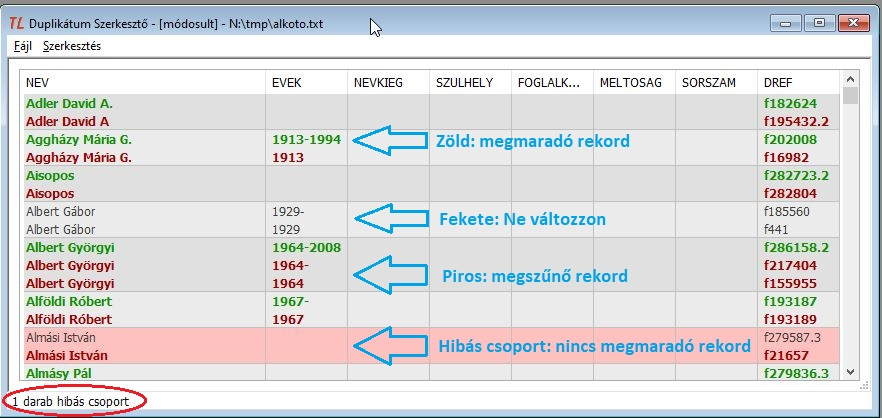
- Megmaradó rekord legyen
A dbdupl program csupán csoportokba sorolja a szövegfájlba kerülés szabályai szerint azonosnak látszó rekordokat, és a csoportok elsőjét zöldnek jelöli. Ez a jelölés tehát nem tekinthető szakmailag alapos döntésnek.
A menüponttal megszűnő rekordot megmaradóvá változtathatunk, pirosból zölddé. Cserébe, az eddig zöld pirossá válik, mivel egy csoporton belül egyetlen zöld sor lehet. A döntésben segít, hogy minden sorban a rekordoknak több mezője is látszik, ezeknek a tartalma alapján lehet megmaradónak kiválasztani a legjobbat.
- Megszűnő rekord legyen
Megszűnőnek jelölhetünk egy eddigi megmaradót. Mivel minden csoportban kell egy megmaradónak lenni, ezzel a lépéssel a csoport hibássá válik. A hibás csoport háttérszíne halvány piros. A hibát úgy javíthatjuk, hogy a csoport valamelyik sorát megmaradónak jelöljük. Ez a végeredmény egyetlen lépésben is elérhető a Megmaradó rekord legyen menüponttal.
Csoportok összevonásával el lehet érni, hogy az egyesített csoportban két megmaradó rekord legyen, de ekkor az egyesített csoport természetesen hibás lesz, amíg az egyik megmaradót megszűnönek nem jelöljük.
7. ábra: Két megmaradó rekord a csoportok összevonásával
- Ne változzon
A menüpont az aktuális sor betűit feketére színezi, ezzel a sor rekordját kivonjuk a további változások alól, megmarad jelenlegi formájában. Erre akkor van szükség, amikor egy csoportnak van olyan tagja, amelyik ugyan a jellemzői alapján a dbdupl program szerint azonosnak tűnik a csoport többi tagjával, de a döntésünk szerint nem azonos egyikkel sem.
Ha egy kéttagú csoport egyik tagját jelöljük meg, a csoport hibássá válik. A híbát úgy javíthatjuk, ha a másik tagot is változatlannak jelöljük, vagy ebből a másikból új csoportot alkotunk.
- Legyen új csoport ebből
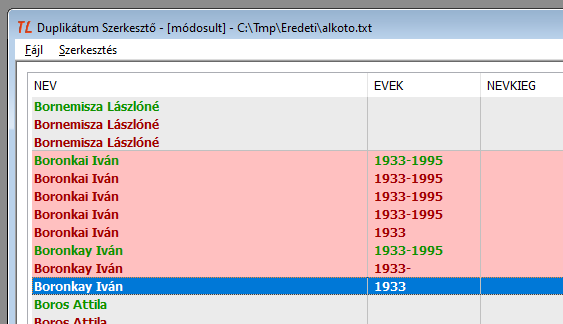
A duplikátum szerkesztő lehetőséget ad arra, hogy a csoportnak egy vagy több tagját kivonjuk a csoportból, és a kivontakat összevonjuk egymással vagy egy következő csoporttal. A könnyebb érthetőség kedvéért álljon itt egy képsorozat:
8. ábra: A kreált példa: Boronkai Iván öt rekordja
9. ábra: A negyedik rekordból új csoportot alkotunk. A rekord az ötödik helyre ugrik, és egytagú csoportként hibásnak jelölődik.
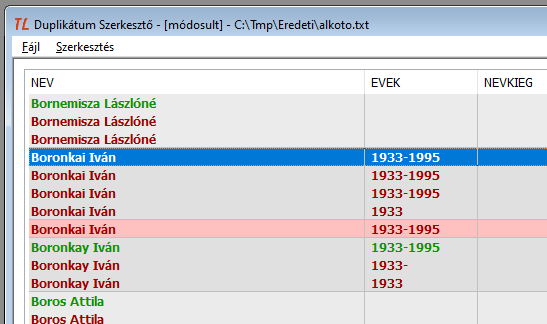
10. ábra: Ismét a negyedik rekordból alkotunk új csoportot. A rekord ismét az ötödik helyre ugrik, és egytagú csoportként hibásnak jelölődik.
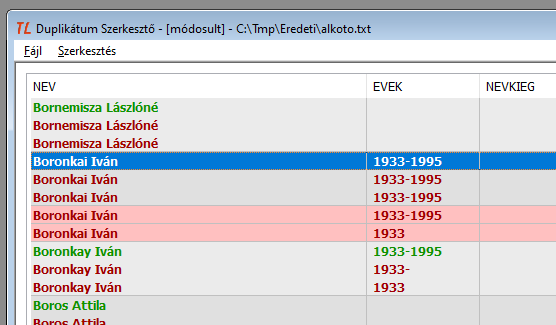
Megjegyzések:
- Az új csoport alkotásához annak bemutatására választottuk mindig az utolsó előtti sort, hogy lássuk a kiválasztott sort a csoport végére ugrani. Azért van így, hogy az új csoporttal tovább lehessen dolgozni, ne maradjanak az elemei az eredeti csoport belsejében szétszóródva.
- A két új csoport automatikusan nem vonódik össze, két hibás sor marad, ha nem teszünk semmit.
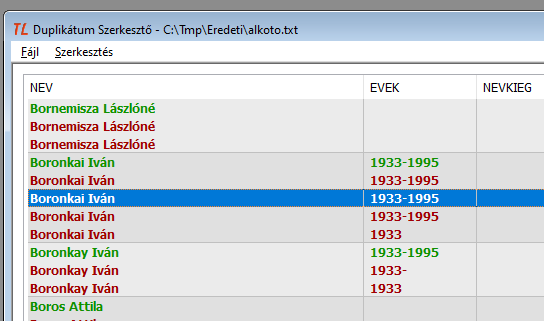
- Összevonás a következő csoporttal
11. ábra: Az első új csoporton állva összevonás a következő csoporttal
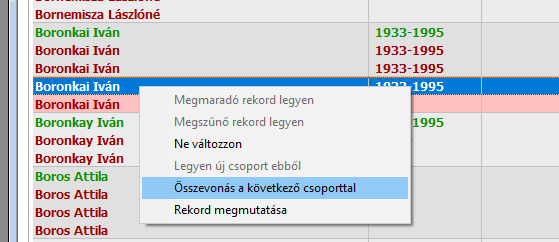
A két csoportból egy lett, de az is hibás. A hibát úgy javíthatjuk, ha az immár egy csoport valamelyik tagját megmaradónak jelöljük.
Egy másik lehetőség, hogy - amennyiben indokolt - a kételemű hibás csoportot összevonjuk az utána következő csoporttal:
12. ábra: A kételemű új csoporton állva összevonás a következő csoporttal
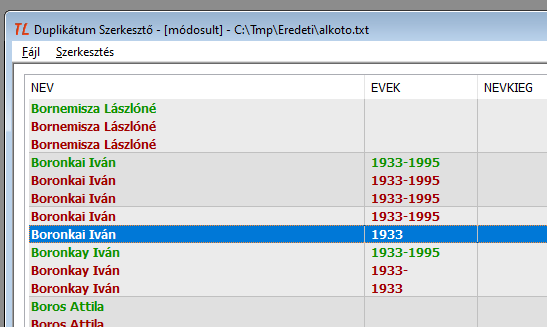
A helyes eljárás talán az lehetett volna, ha az 5 db 'i' vel írt nevet összevonjuk a 3 db ipszilonossal:
13. ábra: Öt 'i' végű + három 'y' végű
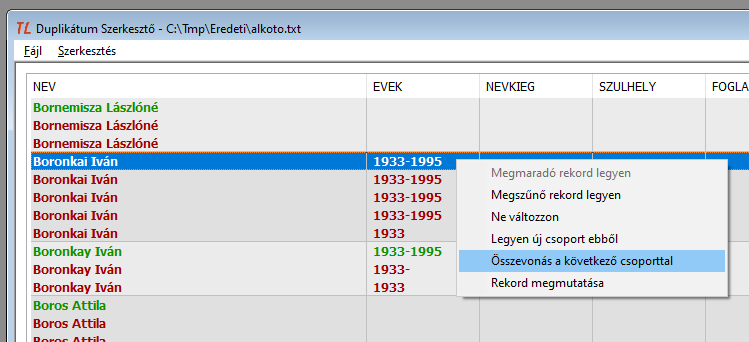
Figyelem! A példák csak példák, a valóságban ezeknek a műveleteknek nem lett volna értelme!
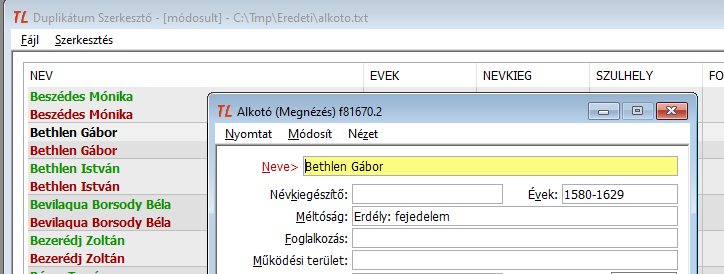
- Rekord megmutatása
Ezt a menüpontot kiválasztva (vagy egyszerűen dupla klikk a bal egérgombbal) a jól ismert ablakos nézetben látjuk a rekordot.
14. ábra: A sor rekordja ablakos nézetben
Következzen egy valóságos példa az egymást követő csoportok összevonására.
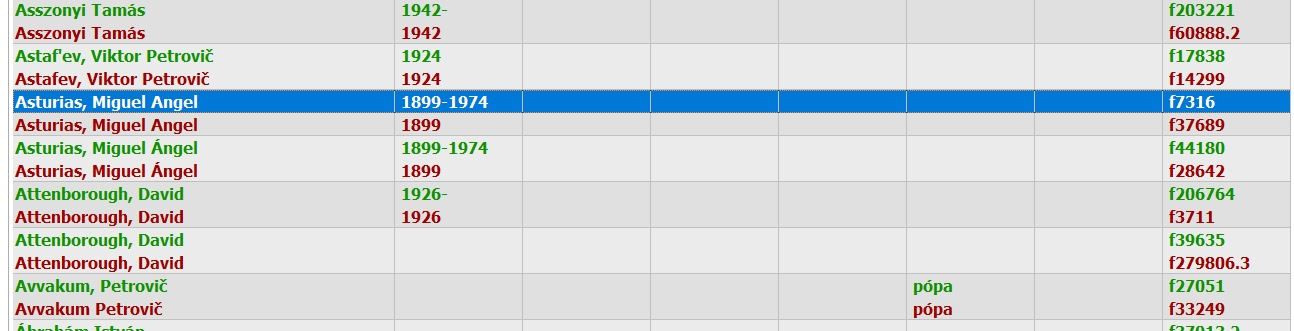
Két nevet is láthatunk a képen, amelyek két különböző okból két-két csoportot alkotnak: Asturias a diakritikus jel miatt, Attenborough pedig a születési évszáma miatt. Ezeket a csoportokat minden valószínűség szerint össze kell vonni.
Az összevonható csoportok többnyire épp közvetlenül egymás után kerülnek a szövegfájlba. Vannak olyan nevek, amikor ez nincs így, pl. a dupla Kis László és a dupla Kiss László nem egymást követő két csoportot alkot. Az ilyet már észrevenni is nehéz, és javítani sem egyszerű. Megtehetjük, hogy megmaradónak jelöljük a Kis Lászlókat és a Kiss Lászlókat, a két név közötti többi nevet véglegesítjük, majd a döntések átvezetésével befejezzük a műveletsort. És mivel tudjuk, hogy a Kis-Kiss probléma és a hasonlók megoldatlanok, újrakezdhetjük a legelején, hiszen biztosak lehetünk abban, hogy a dbdupl program újbóli futása után az új fájlnév.txt-ben már csak néhány megoldatlan duplum lesz.
Térjünk vissza a duplikátum szerkesztő ablak menüjéhez, immár érthetővé váltak a menüpontok:
- Visszavonás: az aktuális soron végzett művelet visszavonása
- Előző hibás csoport: hibás csoportok keresése a fájlban visszafelé
- Következő hibás csoport: hibás csoportok keresése a fájlban előre
- Elemek: a rekordokkal végezhető műveletek
Többször szó esett a hibás sorokról. A munka közben szabad hibás soroknak lenni a fájlban, sőt, el is menthetjük a napi munka végén a hibás fájlt, de a döntések átvezetését végző program már csak hibátlan fájlt fogad el. A véglegesítéshez érdemes tehát a duplikátum szerkesztő ablak menüjéből indulva a hibás csoportokokat keresve áttekintemi a szövegfájlt.
5.3. A döntések átvezetése az adatbázisba
Ezt a műveletet a TextLib szerver gépen végezzük a drefch programmal. A program beszerzéséről és a telepítés helyéről szó volt a duplák keresése pontban. A program indítása:
- Windowsban:
Start - Programok - TextLib Windows Szerver - TextLib Szerver Parancssor ablakban a w-drefch.exe /Xc:\temp\foldrajz.txt paranccsal
- Linuxban:
/usr/share/textlib/exe/g-drefch.exe /X/tmp/foldrajz.txt paranccsal
A /X paraméterrel kell megadni a szövegfájlt. A foldrajz.txt helyébe az éppen feldolgozandó szövegfájl nevét írjuk. Amennyiben az összes szövegfájlt fel akarjuk dolgozni, akkor hétszer kell a drefch programot futtatni. Az ütemezésre nincs ajánlás, tetszés szerinti időpontokat és tetszés szerinti sorrendet választhatunk.
A drefch program végzi a duplumok megszüntetését. Meghagyja a szövegfájl zölddel (megmaradó rekord legyen) és szürkével (ne változzon) jelölt rekordjait, és törli a pirosakat (megszűnő rekord legyen). Pusztán a törlés természetesen kevés lenne, ezért a törlendő rekordokra irányuló összes hivatkozást az egyetlen megmaradóra irányuló hivatkozássá változtataja. E változás után valóban nyugodt szívvel törölhetők a megszűnő rekordok, nem maradnak rájuk irányuló, és emiatt érvénytelenné vált hivatkozások.
A művelet azonban a TextLibben számtalan helyen előforduló adatkapcsolatok miatt közel sem csak ennyiből áll. Tekintsünk példának egy pár alkotó rekordot, ahol az alkotók neve azonos, és mindkettőnek van névváltozata is, ahol az alkotó nevek szintén azonosak.
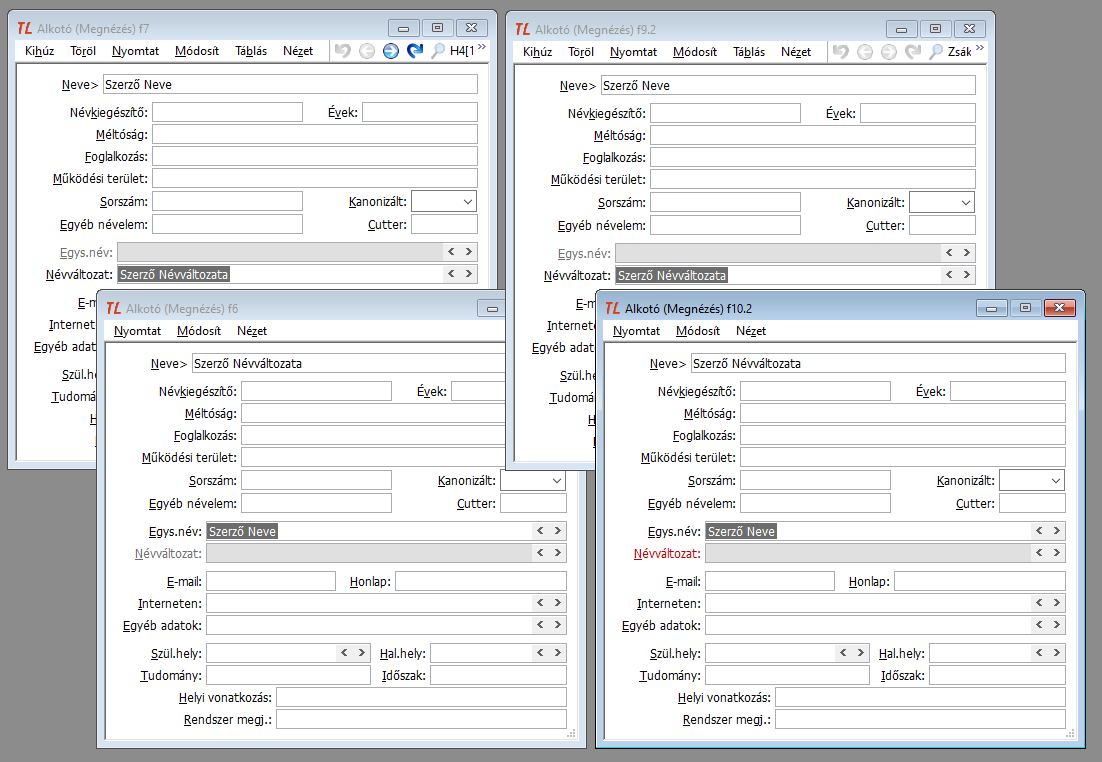
A dbdupl futása után így néznek ki a rekordok a duplikátum szerkesztőben.

Azért, hogy lássuk a drefch program működését egy szélsőséges helyzetben, a névváltozat rekordok közül nem azt jelöltük megmaradónak, amelyik a megmaradó egységesített névalakhoz tartozik. A rekordazonosítók alapján ez könnyen ellenőrizhető.
A drefch program jól kezeli a feladatot, a futását naplózó log így néz ki:
***** 2021-03-11 14:56 **************************************************
w-drefch /Xc:\tmp\alkoto.txt
DREFCHG V3.17 - Dataref csere
- f7.NEVVALTOZAT[0]: f6 -> f10.2
Rekordok törlése...
/ f6 torlese: OK
/ f9.2 torlese: OK
Összesen: 1415 olvasott, 1 módosított, 2 törölt
(0:00, 70750 rek/mp)
Az alábbi sor
- f7.NEVVALTOZAT[0]: f6 -> f10.2
jelentése szerint a drefch program a megmaradó egységesített név rekord (f7) névváltozat mezőjébe beillesztette a megmaradó névváltozat rekord azonosítóját (f10.2). Látható tehát, hogy nem kell tudnunk, a megmaradó-megszűnő döntéskor, hogy egységesített névvel vagy névváltozattal foglalkozunk éppen. Általánosítva leszögezhetjük, hogy a duplikátumok megszüntetésében érintett adatkapcsolatokat a drefch program jól kezeli.
Megjegyzés:
- A drefch.log helye a többi log mellett van, Windowsban az adatbázis mellett C:\textlib, Linuxban pedig a /var/log/textlib mappában.
Az előbbi példánál sokkal bonyolultabb az azonos nevű olvasók egységesítése. A drefch program ugyanis a megmaradónak jelölt olvasó rekordjába összegyűjti a megszűnők összes kölcsönzését, előjegyzését, tartozását stb.
Vissza: Kiegészitő programok TextLib honlap